Поиск по синонимам в тексте — контролируем процесс или доверяемся нейросетям
Время на прочтение
11 мин
Количество просмотров 4.4K

Первое что нужно сделать при разработке поисковых, диалоговых и прочих систем, основанных на natural language processing — это научиться разбирать тексты пользовательских запросов и находить в них сущности рабочей модели. Задача нахождения стандартных сущностей (geo, date, money и т.д.) в целом уже решена, остается лишь выбрать подходящий NER компонент и воспользоваться его функционалом. Если же вам нужно найти элемент, характерный для вашей конкретной модели или вы нуждаетесь в улучшенном качестве поиска стандартного элемента, придется создать свой собственный NER компонент или обучить какой-то уже существующий под свои цели.
Если вы работаете с системами вроде Alexa или Google Dialogflow — процесс обучения сводится к созданию простейшей конфигурации. Для каждой сущности модели вы должны создать список синонимов. Далее в дело вступают нейронные сети. Это быстро, просто, очень удобно, все заработает сразу. Из минусов — отсутствует контроль за настройками нейронных сетей, а также одна общая для данных систем проблема — вероятностный характер поиска. Все эти минусы могут быть совершенно не важны для вашей модели, особенно если в ней ищется одна-две принципиально отличающиеся друг от друга сущности. Но если элементов модели достаточно много, а особенно если они в чем-то пересекаются, проблема становится более значимой.
Если вы проектируете собственную систему, обучаете и настраиваете поисковые компоненты, например от Apache OpenNlp, Stanford NLP, Google Language API, Spacy или Apache NlpCraft для поиска собственных элементов, забот, разумеется, несколько больше, но и контроль над такой системой заметно выше.
Ниже поговорим о том, как нейронные сети используются при поиске сущностей в проекте Apache NlpCraft. Для начала вкратце опишем все возможности поиска в системе.
Поиск пользовательских сущностей в Apache NlpCraft
При построении систем на базе Apache NlpCraft вы можете использовать следующие возможности по поиску собственных элементов:
- Встроенные компоненты поиска, основанные на конфигурации синонимов элементов. Пример описания элементов моделей, основанных на синонимах, Synonym DSL т.д. приведены в ознакомительной статье о проекте.
- Использование любого из вышеупомянутых внешних компонентов, интеграция с ними уже предусмотрена, вы просто подключаете их в конфигурации.
- Применение составных сущностей. Суть — в возможности построения новых NER компонентов на основе уже существующих. Подробнее — тут.
- Самый низкоуровневый вариант — программирование и подключение в систему своего собственного парсера. Данная задача сводится к имплементации интерфейса и добавлении его в систему через IoC. На входе реализуемого компонента есть все для написания логики поиска сущностей в запросе: сам запрос и его NLP представление, модель и все уже найденные в тексте запроса другими компонентами сущности. Эта имплементация — место для подключения нейросетей, использования собственных алгоритмов, интеграции с любыми внешними системами и т.д., то есть точка полного контроля над поиском.
Первый подход, работающий на основе настройки синонимов, не требующий ни программирования, ни текстовых корпусов для обучения модели, является самым простым, универсальным и быстрым для разработки.
Ниже представлен фрагмент конфигурации модели “умный дом” (подробнее о макросах и synonym DSL можно прочесть по ссылке).
macros:
- name: "<ACTION>"
macro: "{turn|switch|dial|control|let|set|get|put}"
- name: "<ENTIRE_OPT>"
macro: "{entire|full|whole|total|*}"
- name: "<LIGHT>"
macro: "{all|*} {it|them|light|illumination|lamp|lamplight}"
...
- id: "ls:on"
description: "Light switch ON action."
synonyms:
- "<ACTION> {on|up|*} <LIGHT> {on|up|*}"
- "<LIGHT> {on|up}"
Элемент “ls:on” описан очень компактно, при этом данное описание содержит в себе более 3000 синонимов. Вот их малая часть: “set lamp“, “light on“, “control lamp“, “put them“, “switch it all“… Синонимы конфигурируются в весьма сжатом виде, при этом вполне читаемы.
Несколько замечаний:
- Разумеется, при работе с поиском по синонимам учитываются начальные формы слов (леммы, стеммы), стоп-слова текста запроса, конфигурируется поддержка прерывистости многословных синонимов и т.д. и т.п.
- Часть сгенерированных синонимов не будет иметь практического смысла, это вполне ожидаемая плата за компактность записи. Если использование памяти станет узким местом (тут речь должна идти о миллионах и более вариантов синонимов на сущность), стоит задуматься об оптимизации. Вы получите все необходимые warnings при старте системы.
Итак вы полностью управляете процессом поиска ваших элементов в тексте запросов, этот процесс является детерминированным, то есть в итоге отлаживаемым, контролируемым, и имеет возможности для последовательного улучшения. Теперь вам нужно лишь аккуратно составить достаточный список синонимов. Здесь вступает в игру человеческий фактор. На этапе старта проекта можно ограничиться лишь несколькими основными синонимами на элемент, достаточно добавить буквально одно-два слова, все будет работать, но в итоге конечно хочется поддержать максимально полный список синонимов для обеспечения наиболее качественного процесса распознавания.
Что может подсказать нам недостающие синонимы в конфигурации, ведь от ее полноты напрямую будет зависеть качество нашей системы?
Расширение списка синонимов
Первое очевидное направление — это в ручном режиме отслеживать логи и анализировать неотвеченные вопросы.
Второе — посмотреть в словаре синонимов, что может быть достаточно полезно для очевидных случаев. Один их самых известных словарей — wordnet.

Работа в ручном режиме может принести определенную пользу, но процесс поиска и конфигурирования дополнительных синонимов элементов здесь явно не стоит автоматизировать.
Помимо этого, разработчики Apache NlpCraft добавили в проект инструмент sugsyn, предлагающий, в процессе использования, дополнительные синонимы для элементов модели.
Компонент sugsyn работает стандартным образом через REST API, взаимодействуя с дополнительным сервером, поставляемым в бинарных релизах — ContextWordServer.
Описание ContextWordServer
ContextWordServer позволяет искать синонимы к слову в заданном контексте. В качестве запроса пользователь передает предложение с помеченным словом, к которому нужно подобрать синонимы, а сервер, используя выбранную модель, возвращает список наиболее подходящих слов заменителей.
Изначально в качестве базовой модели был использован word2vec (skip-gram модель), позволяющий строить векторные представления слов (или эмбеддинги). Идея заключалась в том, чтобы посчитать эмбеддинги слов и основываясь на полученном векторном пространстве отобрать слова, находящиеся ближе всего к целевому.
В целом данный подход работал удовлетворительно, но контекст слов учитывался недостаточно хорошо, даже при больших значениях N для n-граммов. Тогда было предложено использование Bert для решения задачи masked language modeling (поиск наиболее подходящих слов, которые можно подставить вместо маски в предложение). В предложении, которое передавал пользователь, маскировалось целевое слово, и выдача Bert являлась ответом. Недостатком использования одного лишь Bert также было получение не совсем удовлетворительного списка слов, подходящих по контексту использования, но не являющихся близкими синонимами заданного.
Решением этой проблемы стало комбинирование двух методов. Теперь, выдача Bert отфильтровывается, выкидывая слова с векторным расстоянием до целевого слова выше определенного порога.
Далее, по результатам экспериментов, word2vec был заменен на fasttext (логический наследник word2vec), показывающий лучшие результаты. Была использована готовая модель, предобученная на статьях из Wikipedia, а модель Bert была заменена на улучшенную модель — Roberta, смотри ссылку на предобученную модель.
Итоговый алгоритм не требует использования именно fasttext или Roberta в качестве составных частей. Обе подсистемы могут быть заменены альтернативными, способными решить схожие задачи. Кроме того, для лучшего результата предобученной модели могут быть fine-tuned, либо обучены с нуля.
Описание инструмента sugsyn
Работа с sugsyn, удобней всего осуществляется через CLI. Требуется скачать последнюю версию бинарного релиза, использование NlpCraft через maven central в данном случае будет недостаточно.
Общий принцип работы sugsyn достаточно прост. Он собирает примеры использования всех интентов запрашиваемой модели и объединяет их со всеми сконфигурированными синонимами каждого элемента модели. Созданные гибридные предложения посылаются на ContextWordServer, который возвращает рекомендации по использованию дополнительных слов в запрашиваемом контексте. Обратите внимание, для обучения нейронной сети требуются подготовленные и размеченные данные, но для работы sugsyn тоже требуются подготовленные данные — примеры использования, выигрыш в том, что данных для sugsyn нужно совсем немного, кроме того мы используем уже имеющиеся примеры из тестов системы.
Пример. Пусть некий элемент какой-то модели сконфигурирован с помощью двух синонимов: “ping“ и “buzz“ (сокращенный вариант модели, взятой из примера с будильником), и пусть единственный интент модели содержит два примера: «Ping me in 3 minutes» и «In an hour and 15mins, buzz me». Тогда sugsyn пошлет на ContextWordServer 4 запроса:
- text=”ping me in 3 minutes”, index=0
- text=”buzz me in 3 minutes”, index=0
- text=”in an hour and 15mins, ping me”, index=6
- text=”in an hour and 15mins, buzz me”, index=6
Это означает следующее — для каждого предложения (поле “text“) предложи мне какие-нибудь дополнительные подходящие слова, кроме уже имеющихся слов в позиции “index“. ContextWordServer вернет несколько вариантов, отсортированных по итоговому весу (комбинации результатов обеих моделей, влияние каждой модели может быть сконфигурировано), далее отсортированных по повторяемости.
Использование инструмента sugsyn
Приступим к работе
- Запускам ContextWordServer, то есть сервер с готовыми, предобученными моделями.
> cd ~/apache/incubator-nlpcraft/nlpcraft/src/main/python/ctxword
> ./bin/start_server.sh
Обратите внимание на то, что ContextWordServer должен быть предварительно проинсталирован и для успешной работы ему требуется python версий 3.6 — 3.8. См. “install_dependencies.sh“ для linux и mac или мануал по установке для windows. Имейте в виду, что процесс инсталляции влечет за собой скачивание файлов моделей существенных размеров, будьте внимательны. - Запускаем CLI, стартуем в нем server и probe с подготовленной моделью, подробности см. в разделе Quick Start. Для начальных экспериментов можно подготовить свою собственную модель или воспользоваться уже имеющимися в поставке примерами.
- Используем команду sugsyn, с одним обязательным параметром — идентификатором модели, которая должна быть уже запущена в probe. Второй, необязательный параметр — значение минимального коэффициента достоверности результата, поговорим о нем ниже.

Все описанное выше расписано шаг за шагом в мануале по ссылке.
Получение результатов для разных моделей
Начнем с примера по прогнозу погоды. Элемент “wt:phen“ сконфигурирован с помощью множества синонимов среди которых «rain», «storm», «sun», «sunshine», «cloud», «dry» и т.д., а элемент “wt:fcast” с помощью «future», «forecast», «prognosis», «prediction» и т.д.
Вот часть ответа sugsyn на запрос со значением коэффициента minScore = 0.
> sugsyn —mdlId=nlpcraft.weather.ex —minScore=0
"wt:phen": [
{ "score": 1.00000, "synonym": "flooding" },
...
{ "score": 0.55013, "synonym": "freezing" },
...
{ "score": 0.09613, "synonym": "stop"},
{ "score": 0.09520, "synonym": "crash" },
{ "score": 0.09207, "synonym": "radar" },
...
"wt:fcast": [
{ "score": 1.00000, "synonym": "outlook" },
{ "score": 0.69549, "synonym": "news" },
{ "score": 0.68009, "synonym": "trend" },
...
{ "score": 0.04898, "synonym": "where" },
{ "score": 0.04848, "synonym": "classification" },
{ "score": 0.04826, "synonym": "the" },
...
Как мы видим из полученного ответа, чем больше значение коэффициента — тем выше ценность предложенных синонимов для элементов модели. Можно сказать, что интересные для использования синонимы здесь начинаются со значения коэффициента равного 0.5. Коэффициент достоверности результата — интегральный показатель, учитывающий коэффициенты выдачи моделей и частоту, с которой системой предлагается синоним в разных контекстах.
Посмотрим, что будет предложено в качестве дополнительных синонимов для элементов примера “умный дом”. Для “ls:loc”, описывающего расположение элементов освещения (синонимы: «kitchen», «library», «closet» и т.д.), предложенные варианты с высокими значениями коэффициента, большим чем 0.5, тоже выглядят заслуживающими внимания:
"lc:loc": [
{ "score": 1.00000, "synonym": "apartment" },
{ "score": 0.96921, "synonym": "bed" },
{ "score": 0.93816, "synonym": "area" },
{ "score": 0.91766, "synonym": "hall" },
...
{ "score": 0.53512, "synonym": "attic" },
{ "score": 0.51609, "synonym": "restroom" },
{ "score": 0.51055, "synonym": "street" },
{ "score": 0.48782, "synonym": "lounge" },
...
Но около коэффициента 0.5 для нашей модели уже попадается откровенный мусор — ”street”.
Для элемента “x:alarm” модели будильник, с синонимами: ”ping”, ”buzz”, ”wake”, ”call”, ”hit” и т.д. имеем следующий результат:
"x:alarm": [
{ "score": 1.00000, "synonym": "ask" },
{ "score": 0.94770, "synonym": "join" },
{ "score": 0.73308, "synonym": "remember" },
...
{ "score": 0.51398, "synonym": "stop" },
{ "score": 0.51369, "synonym": "kill" },
{ "score": 0.50011, "synonym": "send" },
...
То есть для элементов данной модели, с понижением коэффициента качество предложенных синонимов снижается заметно быстрее.
Для элемента “x:time” модели “текущее время“ (1, 2), с синонимами типа ”what time”, ”clock”, ”date time”, ”date and time” и т.д. имеем следующий результат:
"x:time": [
{ "score": 1.00000, "synonym": "night" },
{ "score": 0.92325, "synonym": "year" },
{ "score": 0.58671, "synonym": "place" },
{ "score": 0.55458, "synonym": "month" },
{ "score": 0.54937, "synonym": "events" },
{ "score": 0.54466, "synonym": "pictures"},
...
Качество предложенных синонимов оказалось неудовлетворительным даже при высоких коэффициентах.
Оценка результатов
Перечислим факторы, от которых зависит качество синонимов, предлагаемых sugsyn для поиска в тексте элементов модели:
- Количество синонимов, определенных пользователем в конфигурации элементов.
- Количество и качество примеров запросов к интентам. Под “качеством“ понимается естественность и распространенность добавленных примеров. Спросите гугл «который час», и число полученных результатов будет “примерно 2 630 000“. Спросите — «час который», результатов будет “примерно 136 000“. Текст первого запроса более качественный, и для примера он подойдет лучше.
- Самое главное и непредсказуемое — качество зависит от типа самого элемента и типа его модели.
Иными словами, даже при прочих равных условиях, таких как достаточное количество заранее сконфигурированных синонимов и примеров использования, для некоторых видов сущностей нейронная сеть предложит более качественный набор синонимов, а для некоторых менее качественный, и это зависит от природы самих сущностей и моделей. То есть для достижения сопоставимого уровня качества поиска, выбирая из списка предлагаемых к использованию синонимов, для разных элементов и разных моделей мы должны использовать разные значения минимального коэффициента достоверности предлагаемых вариантов. В целом это вполне объяснимо, так как даже одни и те же слова в разных смысловых контекстах могут быть заменены несколько разными наборами слов заменителей. Предобученная модель, используемая по умолчанию с ContectWordServer может быть адаптирована для одних типов сущностей лучше чем для других, однако перенастройка модели может и не улучшить итоговый результат. Так как Apache NlpCraft — это opensource решение, вы всегда можете изменить все настройки модели, как параметры, так и саму модель с учетом специфики вашей предметной области. К примеру, для специфичной, изолированной области, имеет смысл обучить модель bert с нуля, поскольку данных об этой области в “стандартной” модели может оказаться недостаточно.
При работе с sugsyn, помимо идентификатора модели, вы можете использовать всего один параметр — minScore, просто ограничивая размер выборки синонимов, отсортированных в порядке снижения их качества. Подобное упрощение используется для облегчения работы специалистов, ответственных за расширение списка синонимов элементов настраиваемой модели. Обилие конфигурационных параметров, свойственное работе с нейронными сетями в данном случае способно лишь запутать пользователей системы.
Заключение
Если вы полностью делегируете задачу поиска ваших сущностей нейронным сетям, то для разных элементов и разных типов моделей вы будете получать результаты, заметно отличающиеся качеством распознавания. При этом вы даже не сможете оценить эту разницу, особенно если вы не контролируете настройки сети. Но и самостоятельная конфигурация для установки желаемого порога срабатывания, не будет являться простой задачей. Причиной, как правило, является недостаток достаточного количества данных, необходимых для корректного обучения и тестирования сети. Используя предлагаемый Apache NlpCraft механизм поиска сущностей через набор синонимов и инструмент, предлагающий варианты обогащения данного списка, вы можете самостоятельно контролировать степень достоверности синонимов вашей модели и выбрать из предлагаемых сетью только одобренные вами подходящие варианты. Фактически вы получаете возможность заглянуть в черный ящик и достать из него лишь то, что вам нужно.
Компьютеры понимают только числа. Чтобы обучить машину естественному (человеческому) языку, мы должны перевести все слова в числовой формат. Для этого можно использовать встраивание слов — Word2Veс.

Вместе с Марией Обедковой, NLP Engineer в TrustYou, разбираемся, как работает Word2Vec (на примере Python-библиотеки Gensim).
Как превратить текст в числа
Обработка естественного языка (NLP) начинается с преобразования текста в числа — векторизации. Текст разбивают на части (токены) — символы, слова или предложения, — а затем присваивают числовое значение каждой части (в зависимости от частоты, с которой токен встречается в тексте). Токену можно назначить не одно число, а вектор, состоящий из нескольких чисел.
Word2Vec — одна из реализаций предварительно обученного векторного представления слов от Google.
Создавать векторы можно с помощью подходов One-Hot Encoding и Embedding. В One-Hot Encoding каждый вектор состоит из количества чисел, совпадающего с числом слов в тексте. Все элементы вектора равны 0, кроме того, который соответствует токену.
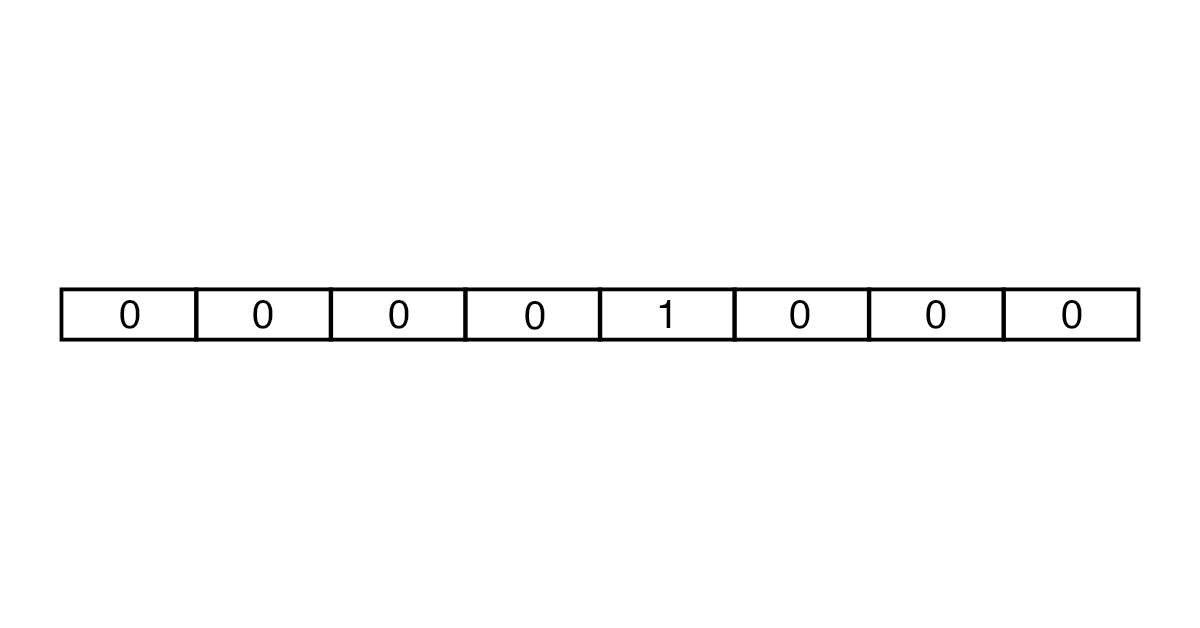
Сначала количество слов для анализа ограничивается с помощью словарей. Для английского языка, например, используют словари Oxford 3000 и Merriam-Webster. Затем создается вектор нужной длины из множества нулей и одной единицы. В итоге получаются векторы большого размера, которые занимают много места в памяти.
Embedding считается более эффективным и менее ресурсоемким. В таком случае вектор может состоять не только из 0 и 1, но и из других чисел. Понадобится меньше «ячеек», чтобы преобразовать слово.
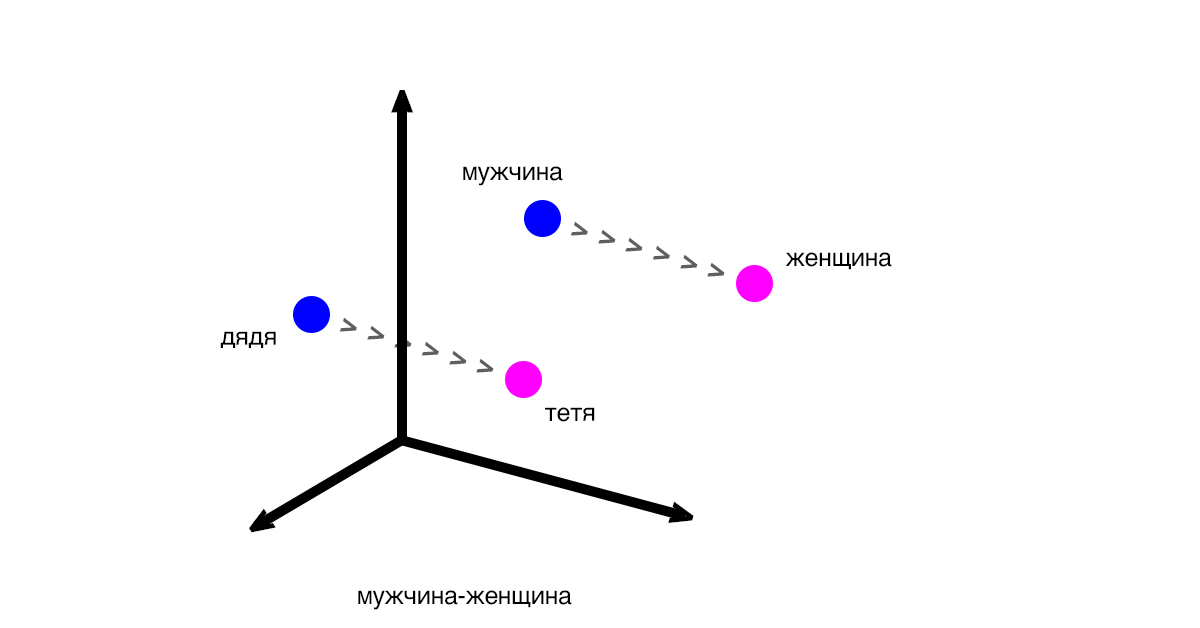
Векторы показывают разницу и закономерности между частями текста (словами, предложениями). Классический пример: вектор между словами «мужчина» и «женщина» будет таким же, как и вектор между словами «дядя» и «тетя».
Расстояния между векторами соответствуют смыслу слов. Выражение «дядя» — «мужчина» + «женщина» будет близким к «тетя», но при этом может не соответствовать ему на 100%.
Мария: «Word2Vec используют как основу для больших проектов и как способ решения исследовательских подзадач. При этом у идеи дистрибутивной семантики (того, что слово можно идентифицировать по контексту) есть недостатки. Например, схожесть слов не всегда указывает на то, что они одинаковы по смыслу».
Поиск синонимов: пишем скрипт
Для работы с Word2Vec можно использовать библиотеку Gensim. Она помогает обрабатывать естественные языки и извлекать семантические темы из документов. Gensim «перегоняет» текст в вектор и считает расстояние между векторами. Преимущество библиотеки в том, что она не требует полной загрузки корпуса в память, а позволяет читать данные с диска.
Рассказываем на примере, как векторные представления помогают находить синонимы для улучшения работы поисковых запросов.
- 1. Загрузим библиотеки для парсинга и анализа страниц.
pip install beautifulsoup4 pip install lxml - 2. Приступим к написанию скрипта и подтянем необходимые зависимости (для парсинга, работы с регулярными изображениями, NLP и Gensim).
import bs4 as bs import urllib.request import re import nltk from nltk.corpus import stopwords from gensim.models import Word2Vec - 3. Будем парсить страницу «Википедии» о романе Филипа Дика Do Androids Dream of Electric Sheep.
scrapped_data = urllib.request.urlopen('https://en.wikipedia.org/wiki/Do_Androids_Dream_of_Electric_Sheep') article = scrapped_data.read() - 4. С помощью объекта BeautifulSoup извлекаем из абзацев текст.
parsed_article = bs.BeautifulSoup(article, 'lxml') paragraphs = parsed_article.find_all('p') - 5. Объединяем весь текст в переменной article_text.
article_text = "" for p in paragraphs: article_text += p.text - 6. Дальнейшая работа любого скрипта зависит от того, насколько хорошо вы провели очистку исходного текста. Поэтому мы переводим все символы в нижний регистр.
cleaned_article = article_text.lower() - 7. Оставляем только буквы и убираем пробелы, используя регулярные выражения.
cleaned_article = re.sub('[^a-z]', ' ', cleaned_article) cleaned_article = re.sub(r's+', ' ', cleaned_article) - 8. Готовим датасет для обучения.
all_sentences = nltk.sent_tokenize(cleaned_article) all_words = [nltk.word_tokenize(sent) for sent in all_sentences] - 9. Проходимся по датасету и удаляем стоп-слова (те, которые не добавляют смысла, например, is).
for i in range(len(all_words)): all_words[i] = [w for w in all_words[i] if w not in stopwords.words('english')] - 10. Создаем модель Word2Vec со словами, чаще всего встречающимися в тексте. Например, теми, которые встречаются минимум 3 раза (min_count=3).
word2vec = Word2Vec(all_words, min_count=3) - 11. В рамках модели находим и выводим самое близкое по смыслу (topn=1) слово для book.
print(word2vec.wv.most_similar('book', topn=1))
Готово — ближайший синоним слова book по нашему словарю — novel.
[(‘novel’, 0.26558035612106323)]
Таким же образом можно искать близкие значения к отдельным словам и целым запросам.

Пример. Пусть мы занимаемся описанием intents для голосового ассистента. Мы создали простую семантическую модель, где определили некий набор элементов. Подробнее по ссылке. Среди прочих сущностей, мы описали элемент ”web user” co следующим набором синонимов:
- web user,
- site user,
- online user
Далее мы анализируем пользовательский запрос
Show me web user data
и пытаемся найти в нем сконфигурированные элементы модели.Как происходит поиск сущности “web user” в тексте запроса?
Все начинается с токенизации.
Токенизация
Токенизация это процесс, являющийся частью лексического анализа, при котором текст, в нашем случае пользовательский запрос, разбивается на токены. В случае одного предложения это просто слова.
Зачем это нужно? Для того чтобы мы могли осуществлять поиск внутри текста по отдельным словам и словосочетаниям.
В простейшем случае мы можем разбить предложение на токены, ориентируясь лишь на пробелы между словами. На практике ситуация сложнее, так как необходимо поддерживать такие символы разделители как тире, многоточие, кавычки, восклицательные и вопросительные знаки, точки, кроме того специальным образом обрабатывать точки при использовании в сокращениях и так далее. Помимо этого, нам приходится принимать во внимание некоторые дополнительные особенности, присущие разным языкам. Так, например, в немецком из-за характерной для этого языка практики построения сложносоставных слов, простой токенизации будет недостаточно.
Пример. Составное слово “der Wintersport“ (Winter + Sport) — зимний спорт (зима + спорт).
Если необходимо найти слово “спорт“, вам придется каким-то образом разбить монолит “Wintersport“ для успешного поиска нужного слова внутри составного.
В целом задача токенизации текста уже успешно решена многими NLP продуктами и у нас нет необходимости заниматься ей самостоятельно, мы всегда можем пользоваться многообразием существующих на рынке NLP решений.
Идем дальше, нормализуем токены.
Леммы и стеммы
На следующем этапе морфологического разбора текста пользовательского запроса все слова в предложении (токены) нормализуются специальным образом, в результате чего каждому слову ставится в соответствие его лемма и стемма.
- Лемма — начальная словоформа.
- Стемма — основа слова. Она может быть получена с помощью различных алгоритмов, например с помощью алгоритма Портера.
Задача нормализации также успешно решена различными NLP продуктами и мы лишь пользуемся результатами их работы.
Зачем это делать? Для того чтобы сократить до разумного количества число синонимов, описывающих элементы модели.
Пример. Два предложения:
- Show me online user data
- Show me online users data
Разумеется понятие “web user” должно быть определено один раз для обоих случаев синонимом “online user“. Таким образом, нам следует искать заранее нормализованные синонимы среди также нормализованных слов (токенов) рассматриваемого предложения.
Примечание. В общем случае лучше всего осуществлять поиск в несколько итераций, например:
- пытаемся найти по оригинальной версии слов, далее
- по нормализованным версиям — стеммам, далее
- по нормализованным версиям — леммам
Что лучше использовать стеммы или леммы? Зависит от ситуации. Например, для русского языка стемминг работает хуже чем для ряда прочих из-за относительного большого количества случаев супплетивизма, таких как “идти — шла”. Данные словоформы одного слова просто не имеют общего корня, и тут нам на помощь приходит лемматизация.
С другой стороны процесс стемминга гораздо проще алгоритмически. Он не требует, что бывает важно, наличия полноценного NLP процессора ни на стороне где происходит загрузка синонимов, ни на стороне разбора запроса. Кроме того алгоритм стемминга не нуждается в контексте вопроса, зачастую необходимого для процесса лемматизации.
Обработка стоп-слов
Ок, мы нормализовали слова в тексте и теперь пытаемся осуществить среди них поиск по нормализованным синонимам разыскиваемых сущностей. Пусть, опираясь на определенные выше примеры, мы хотим отыскать элемент “web user” в следующем предложении:
Show me online users data
Для нас не составит труда найти сущность “web user” по синониму ”online user”, встреченному в запросе. А найдется ли элемент “web user” в таком запросе?
Show me online an user
Нет — не найдется.
Игнорируем корректность применения артикля в данном предложении.
Причина — у нас определен синоним “online user”, но не определен “online an user”.
Решение — мы должны искать совпадения лишь по значимым словам предложения, игнорируя стоп-слова. В нашем примере поиск должен осуществляться только в следующем наборе слов “show me online user”. Стоп-слово “an” должно быть проигнорировано при анализе.
Примечание
Когда пользователь системы определяет всевозможные синонимы, он может осознанно или случайно использовать стоп-слова в элементах своего списка. Не стоит запрещать ему делать это. Например задача найти в тексте название газеты “The Sun”. Мы не сможем найти его в тексте, заранее очищенном от стоп-слов. Таким образом, мы должны пытаться искать синонимы в два этапа: сначала среди всех слов и лишь затем исключив стоп-слова.
Итого, на этапе лингвистического анализа мы должны получить все токены предложения, размеченные флагами — является ли рассматриваемое слово стоп-словом или не является.Коллизии, возникающие при работе с синонимами
Пусть наша модель помимо элемента “web user” имеет еще одну описанную сущность: “компания“ с названием “americas multimedia online”. Как распознается следующий вопрос:
Americas multimedia online user?
В нем обнаружатся обе сущности:
- “americas multimedia online“ — ”компания”
- “online user“ — ”web user”
Человеку очевидно, что в данном примере следует оставить лишь элемент “компания”, а “web user” здесь не при чем. Но как разрешить возникшую коллизию алгоритмически?
В нашем примере это довольно просто. Должен “выигрывать“ синоним, а вместе с ним и сущность, содержащий большее количество слов — три слова для “americas multimedia online” против двух слов для “web user”.
Как правило, на практике разрешение подобных коллизий является более сложной задачей, но в основе решения всегда будет лежать схожая по сути система приоритетов.
Поиск “прерывистых“ синонимов
Возвращаемся к нашему примеру по нахождению сущности “web user”. Как нам найти и можем ли мы вообще обнаружить эту сущность в вопросе:
Give me users with status online?
Очевидно, что наиболее подходящий синоним среди всех определенных нами это — ”online user”. Но в рассматриваемом предложении изменен порядок слов в словосочетании, и, кроме того, между словами ”online” и “user” затесалось еще два — ”status” и “with”.
В DataLingvo мы предоставляем пользователям возможность настройки специального коэффициента — “JIGGLE_FACTOR”. Данный параметр определяет, на сколько позиций может быть сдвинуто слово в предложении относительно ожидаемой позиции в синониме, для того чтобы данный синоним был успешно распознан.
В предложении “Give me users with status online” слово “online“ сдвинуто на 4 позиции относительно расположения в исходном ожидаемом синониме ”online user”. Таким образом, настраивая систему, пользователь может определить насколько “строгим” должен быть поиск в пределах:
- от максимально строгого, когда порядок слов в синонимах жестко определен и не может быть изменен, то есть допустимый сдвиг между словами равен нулю
- до более “либерального”, позволяющего искать синонимы в тексте с учетом возможных перестановок.
Какой вариант стоит выбрать зависит исключительно от типа вашей модели.
Примечание. Необходимость использования системы приоритетов для выбора между потенциально найденными синонимами при поиске с перестановками актуальна как никогда. Изначально должны ”выигрывать” те синонимы, для которых сумма перестановок всех их токенов минимальна, но с другой стороны количество слов в синониме может в свою очередь перевешивать этот фактор, и так далее. Алгоритмы разрешения подобных коллизий могут быть достаточно нетривиальными, но все эти вопросы выходят за рамки примера.
Послесловие
Мы описали основные базовые шаги и принципы, по которым осуществляется поиск в тексте сущностей семантической модели, и были вынуждены отбросить ряд важных, но как надеемся, несущественных для понимания общей картины деталей. Данные принципы достаточно едины и в целом не зависят от поставщика NLP решения. Иногда задача разбора текста может быть упрощена — для некритичных систем, иногда должна быть существенно усложнена, но в целом все подобные системы имеют схожую структуру и опираются на единые принципы.
Похоже, на русском языке нет полного обзора по современным методам аугментации при работе с текстами, поэтому появился этот… На английском языке есть несколько очень хороших, но здесь удалось осветить более свежие научные работы. Целевая аудитория обзора — начинающие в NLP.

Аугментация (augmentation) – это построение дополнительных данных из исходных при решении задач машинного обучения. Обычно при аугментации применяют преобразования исходных объектов, которые не меняют их метки, но меняют (иногда существенно) описания. Например, если мы, тренируя нейросеть, которая должна отличать фотографии кошек от фотографий собак, будем вращать, растягивать, менять яркость и контрастность исходных изображений, то это не изменит того, что на них изображено, но даст возможность обучиться сети на «плохих», деформированных фотографиях, а также на ракурсах, которые могут быть в недостатке в обучающей выборке.
Аугментация текстов немного сложнее аугментации изображений. Во-первых, преобразуя текст больше шансов исказить его смысл (или вообще получить бессмысленный текст). Во-вторых, здесь преобразования «менее автоматические». Например, чтобы повернуть фотографию не надо быть фотографом или знать законы оптики, а вот чтобы перефразировать какое-то предложение надо быть, по крайней мере, носителем языка (а также знать синонимы, контекст и т.п.)
Недостижимая мечта при аугментации текста это как раз перефразирование, например,

Для себя автор систематизировал аугментации текста следующим образом:

Ниже опишем каждый из перечисленных видов аугментации.
Замена синонимом
Самый простой способ перефразировать — заменять слова синонимами (Synonym Replacement). Обычные замены с помощью словаря синонимов рассматривались в работе Zhang et al. Character-level Convolutional Networks for Text Classification. Ниже в примере показано, что подобная замена может быть и некорректной. Так, слово «лёгкие» может быть существительным или прилагательным, при этом совершенно меняя смысл. Обычно при замене не выбирают стоп-слова (артикли, предлоги, союзы и другие очень часто встречающиеся слова, которые не передают основной смысл текста).

Сокращения
Можно как применять какие-то принятые сокращения (так как = т.к., так далее = тд), так и «раскрывать эти сокращения». Есть списки подобных принятых сокращений. Например, для английского языка такой список есть на Wiki. Не все сокращения можно однозначно раскрыть, например в английском языке «He’s» может означать «Не is», а может «He has». Есть библиотека для подобных аугментаций.
Использование представлений слов
Случайные слова заменяем на близкие к ним в пространстве представлений (Word Embeddings). Как показано в примере, здесь не всегда используются синонимы. Часто — слова, которые употребляются в похожих контекстах или вместе с заменяемым словом. Чтобы обезопасить себя от нежелательных замен, можно заменять только словом той же части речи.

Такую аугментацию применяли в работе Wang and Yang «That’s So Annoying!!!: A Lexical and Frame-Semantic Embedding Based Data Augmentation Approach to Automatic Categorization of Annoying Behaviors using #petpeeve Tweets»
Использование контекстных представлений
Кроме классических представлений (Word2Vec, fasttext, GloVe), можно использовать те, которые учитывают контекст слова (его окружение другими словами). В работах Marzieh Fadaee et al. «Data Augmentation for Low-Resource Neural Machine Translation», Kobayashi «Augmentation: Data Augmentation by Words with Paradigmatic Relation» для построения таких представлений использовались двунаправленные LM (языковые модели). Языковые модели, вообще говоря, получают не конкретное слово, а распределение на множестве слов. Поэтому для замены можно использовать любое слово, которому соответствует высокая вероятность.
В последние годы популярны модели на базе архитектуры трансформера. В частности, их обычно предобучают на больших наборах данных заполнять маскированные токены, по-простому, восстанавливать пропущенные слова. Поэтому такие модели логично использовать для замены слов: заменяем некоторые слова на маски и подаём на вход трансформеру, а он «превращает» маски в слова. В работе Garg. et al. «BAE: BERT-based Adversarial Examples for Text Classification» модель BERT использовалась для подобной замены, а также для вставок слов (можно между любыми словами в предложении поместить маску, модель заменит её на подходящее слово). Ниже показан поясняющий рисунок из статьи.

Замена и удаление несущественного / существенного
Один из основных вопросов, связанных с заменой или удалением слов при аугментации: какие слова лучше заменять / удалять? Причём на него разные авторы дают часто совсем противоположные ответы. В Xie et al. «Unsupervised Data Augmentation» предложено заменять несущественные слова — слова с маленьким значением TF-IDF. Пример подобной замены приведён ниже:

В Hanjie Chen «Improving the Explainability of Neural Sentiment Classifiers via Data Augmentation», напротив, предложено заменять самые значимые слова. Так, в задаче определения сентимента можно находить самое «сентиментное» слово и удалять его (например, слова «отличный», «превосходный», «классный», «улётный» и т.п.). Положительный отзыв на фильм должен определяться нашим алгоритмом как положительный и без явных эпитетов (а на основе отсутствия критики, построения повествования и т.п.). Кроме того, в указанной работе в тексты добавлялись т.н. состязательные примеры (Adversarial Examples), т.е. слова, которые приводят к неправильной классификации и «путают» алгоритм.
При заменах также иногда анализируют контекст. Например, в работе Jacob Andreas «Good-Enough Compositional Data Augmentation» предложен метод GECA (good-enough compositional augmentation), который анализирует то, что авторы назвали «лексическим окружением» слова. Скажем, в предложениях
- Я устал и хочу спать прямо сейчас.
- Я выпил и хочу танцевать прямо сейчас.
выделенные слова имеют одинаковое окружение, а значит допустимы замены устал-выпил и спать-танцевать (что немного спорно, но работает в некоторых задачах).
Обратный перевод (Back Translation)
При наличии хороших автоматических переводчиков часто текст переводят на другой язык, а затем переводят «обратно» на исходный. Понятно, что при этом как раз получается перефразировка исходной фразы. Такой метод использовался, например, в работе Xie et al. «Unsupervised Data Augmentation», а также победителем Kaggle-соревнования «Toxic Comment Classification Challenge». Есть несколько полезных заметок, посвящённых обратному переводу:
- https://amitness.com/2020/02/back-translation-in-google-sheets/
- https://amitness.com/back-translation/
Есть несколько приёмов, применяемых при обратном переводе, которые увеличивают число возможных аугментаций. Первый — перевод можно осуществлять на разные языки. Второй — можно играться с настройкой языковой модели, которая формирует текст перевода (генерируя чуть менее вероятные, с точки зрения LM, тексты, которые могут быть удачными перефразировками). Как показано в примере ниже, современный google-translate также не справляется со словом «лёгкие» в нашем примере.

Зашумление
Под зашумлением понимаются разные способы испортить текст, которые, впрочем, типичны для текстов. Можно добавлять ошибки в буквах, знаках препинания, менять регистр. При добавлении ошибок можно стараться их делать так, чтобы они были похожи на те, что совершаются при наборе (например, символ заменять на другой исходя из близости соответствующих клавиш на клавиатуре).

Можно удалять слова или заменять их специальным токеном (Blank Noising), переставлять слова (Random Swap), а также целые предложения (Sentence Shuffling).
Интересный приём, который редко делают — случайная вставка / Random Insertion (RI), когда в предложение в случайное место вставляется синоним случайного слова этого же предложения, подробнее см. в Wei et al. «EDA: Easy Data Augmentation Techniques for Boosting Performance onText Classification Tasks». Пример применения случайной вставки показан ниже:

Кроссовер
Довольно оригинальный и простой приём аугментации предложен в Franco M. Luque «Atalaya at TASS 2019: Data Augmentation and Robust Embeddings for Sentiment Analysis». Для генерации новых объектов класса берём два его представителя: A и B. Каждый из этих текстов делим пополам, получаем тексты A = A1 + A2, B = B1 + B2, где плюс означает конкатенацию. После этого тексты A1 + B2 и B1 + A2 добавляются в обучение. Пример применения кроссовера показан ниже:

Понятно, что описанный метод применим только в задачах с размеченными данными, а также с достаточно большими текстами (например, в задаче классификации фраз диалога тексты состоят из 1-2 предложений, поэтому применение кроссовера не выглядит разумным). В оригинальной статье кроссовер не влиял на точность классификации в задаче анализа сентимента, но увеличивал F1-меру.
MixUp для текстов
Аугментация MixUp хорошо зарекомендовала себя для изображений и табличных данных. При её использовании берутся два объекта, выбирается коэффициент λ∈(0,1), новый объект, добавляемый в обучение, является линейной комбинацией с коэффициентами λ, 1-λ выбранных объектов (неформально говоря, объекты «смешиваются»). Его метка также является линейной комбинацией с такими же коэффициентами меток выбранных объектов (тут есть некоторая тонкость, но мы её пропустим). С текстами есть проблема в применении этого метода, т.к. тексты дискретны и не понятно, что такое линейная комбинация текстов. В работе Hongyu Guo «Augmenting Data with Mixup for Sentence Classification: An Empirical Study» предложено несколько вариантов обобщения MixUp на тексты. Можно «смешивать» тексты следующим образом
- Выравниваем два текста по длине (более короткий дополняем спец-токенами). Новый текст будет иметь такую же длину, его i-е слово с вероятностью λ является i-м словом первого текста и с вероятностью 1-λ — i-м словом второго текста. Это логично назвать равномерным кроссовером предложений.
- Аналогичная процедура, но теперь для каждого i берём представление (word embedding) i-х слов первого и второго текста. Вычисляем линейную комбинацию представлений с коэффициентами λ, 1-λ. В новом тексте i-е слово выбирается так, чтобы его представление было ближайшим к полученной линейной комбинации. Такой способ называтеся wordMixUp.
- Если в нейросети, которая решает задачу, используются представления предложений (Sentence Embeddings), то логично организовывать линейную комбинацию над ними. Представления предложений в простом варианте являются усреднением представлений слов предложения, а в более сложном вычисляются модулем нейросети по токенам предложения. Строго говоря, это не совсем аугментация, т.к. мы можем в явном виде не пополнять выборку новыми объектами, но это более логичная процедура, которая называется senMixUp.

Совсем недавно (в прошлом месяце) в работе R Zhang «Seqmix: Augmenting active sequence labeling via sequence mixup» предложены модификации MixUp для текста в задаче с метками токенов (каждый токен имеет некоторую метку, например такое имеет место в Named entity recognition). Основная идея — подвергать смешиванию не полные предложения, а их подфрагменты, в простой реализации авторы назвали такую аугментацию Sub-sequence mixup. В более сложной предполагается смешивание только специальных подфрагментов: ищутся последовательности токенов, у которых одинаковые соответствующие им последовательности меток. Тогда при смешивании не нужно делать линейную комбинацию меток, достаточно смешивать описания токенов подпоследовательностей, см. рис. Такая аугментация называется Label-costrained Sub-sequence mixup.

Синтаксическое дерево
По аугментируемому предложению можно построить синтаксическое дерево разбора, тогда можно перейти к эквивалентному дереву и по нему перестроить предложение. Подобный подход применялся в работе Coulombe «Text Data Augmentation Made Simple by Leveraging NLP Cloud APIs», см. рис.

Генеративные модели
Для синтеза новых данных можно использовать генеративные модели, которых сейчас довольно много. Можно взять, например, языковую модель и донастроить её на обучающую выборку в конкретной задаче. Более того, можно предварительно донастроить её на похожих задачах, а также провести обуславливание (генерация будет проводиться при определённых условиях), например, генерация начинается с метки, а потом идёт текст. В этом случае, в задаче определения сентимента, если модели подать на вход начало текста с меткой «POSITIVE», то она породит текст позитивной тональности. Подобные подходы рассматривались в работах Kafle et al. «Data Augmentation for Visual Question Answering» и Kumar et al. «Data Augmentation using Pre-trained Transformer Models». Опишем для примера метод LAMBADA (Language Model Based Data Augmentation) из работы Anaby-Tavor et al. «Not Enough Data? Deep Learning to the Rescue!».
- На обучающей выборке обучаем классификатор.
- Донастраиваем на этой же выборке предварительно обученную языковую модель.
- Синтезируем с помощью модели объекты с конкретными метками.
- Прогоняем классификатор на синтезированных объектах. Если он уверенно приписывает объекту его метку, то пополняем этим объектом выборку, в противном случае удаляем его.
Некоторые новые аугментации
Довольно много статей по описанному выше генеративному подходу с приложениями в медицине. В частности, довольно много появляется работ, в которых трансформеры используются для синтеза медицинских текстов (приведём работу Exploring Transformer Text Generation for Medical Dataset Augmentation для примера). Строго говоря, в них часто речь идёт не об аугментации, а о создании эквивалентного датасета. В медицине истории болезней пациентов относятся к т.н. персональным данных, а следовательно, их нельзя выкладывать в открытый доступ и сравнивать на них различные подходы в «воспроизводимом и верифицируемом формате». Поэтому есть надежда использовать для исследовательских целей синтетические датасеты.
Из интересных направлений упомянем использование RL для аугментации. В работе Zhiting Hu et al «Learning Data Manipulation for Augmentation and Weighting» предлагается выбор аугментации и весов объектов обучающей выборки рассматривать как выбор стратегии некоторого игрока. Качество решения исходной задачи при этом соответствует награде, здесь она называется «data reward«. Соответственно, предлагается алгоритм для максимизации этой награды.
Ссылки
Описанный выше обзор есть и в форме видеодоклада, который делался на научном семинаре компании dasha.ai, а потом в изменённом виде на спецсеминаре в МГУ. Видео с последнего мероприятия представлено ниже:
Также рекомендуем следующие источники:
- заметка в блоге «Data augmentation in NLP» https://towardsdatascience.com/data-augmentation-in-nlp-2801a34dfc28
- заметка в блоге «Data augmentation for NLP» https://amitness.com/2020/05/data-augmentation-for-nlp/
- Статьи с доступной реализацией аугментации https://paperswithcode.com/task/text-augmentation
- Библиотека nlpaug https://github.com/makcedward/nlpaug
- Библиотека https://github.com/QData/TextAttack