Поиск «Битрикс» хорош. Но не идеален. И на большинстве сайтов явно не дотягивает до уровня поисковых машин Яндекс и Google. Поиск «Битрикс» по сайту не умеет обучаться сам. Значит, надо ему помогать вручную. Иначе вы не сможете продать USB-накопители, если посетители будут искать флешки. И наоборот. Как повысить эффективность поиска по сайту?
1. Создадим поле для ввода синонимов
Инфоблоку товаров добавим еще одно свойство. Назовем его «Синонимы для поиска по сайту». Назначим текстовый тип и поставим галочку, чтобы записи этого поля индексировались внутренним поиском. Определим его как обязательное для заполнения.
2. Где брать синонимы?
Теперь при добавлении нового товара оператор должен будет обязательно заполнить синонимы через запятую. В помощь тут будут Яндекс Wordstat, выдача Яндекса и Google, отзывы на Яндекс.Маркете, сайты конкурентов. Например, если краска бирюзовая, можно добавить синонимы «зеленая», «зеленоватая», «сине — зеленая». Для клавиатуры, естественно, добавим «клава», «батон», для материнской платы «мать». Если названия или имена производителей на других языках (например, английском), обязательно добавляйте варианты на русском языке. «Nike» — «Найк», «Android» — «Андроид» и так далее.
3. Не бойтесь поисковых санкций
Но и не подставляйтесь под них. Синонимы и жаргонизмы должны применяться исключительно для внутреннего поиска. Индексация поисковыми машинами Яндекс и Google должна быть запрещена. Позаботьтесь об этом.
4. Не вводите в заблуждение
У вас будет искушение поспамить в список синонимов, подсовывая посетителям «почти то», «похоже», или «совсем не то, но вдруг купят». Купят мало, зато поймут, что поиск работает «не так» и перестанут им пользоваться. Или вообще уйдут от вас.
5. Варьируйте разные параметры
Добавляйте кириллические синонимы не только к бренду, но и к размеру, цвету, названиям протоколов. Ищите, расспрашивайте.
6. Находки для поисковой оптимизации
В пункте 3 мы предупреждали, что списки синонимов должны быть недоступны для индексации «большими» поисковыми машинами. Из этого правила есть исключения: единичные, популярные у покупателей и релевантные синонимы можно и нужно выводить в мета-теги для индексации Яндекс и Google. Это улучшит положение в выдаче и посещаемость.
——————————-
Спасибо за внимание!
Читайте свежий выпуск «Кладовки программиста» каждый день!
Назад в раздел
![]()
Разработчиком данного модуля является 7 Studio
-
Подходящие редакции 1С-Битрикс:
Малый бизнес, Бизнес -
Включает в себя:
Компоненты, Переводы -
Категории:
Для интернет-магазина, Инструменты, Контент-менеджеру, Каталог товаров, Свойства, фильтр, поиск, Работа с текстами
-
Название компании-партнера:
7 Studio -
Последняя версия:
1.1.4 -
Дата публикации:
02.12.2021 -
Число установок:
Менее 50 раз -
Адаптивность:
Нет -
Поддержка композита:
Нет -
Совместимо с Сайты24:
Нет
Усовершенствование поиска основано на использовании дополнения поисковой фразы синонимами.
Например для поисковой фразы смартфон можно создать синонимы такие как: телефон, мобила, труба.
Для фразы «Клавиатура» можно использовать такой синоним как «клава».
Поле «вес» используется для удобства управления синонимами в списке (сортировка и фильтрация списка). В поле вводятся значения в виде целых положительных чисел.
Решение расширяет базовый функционал стандартного модуля «Поиск» от Битрикс, позволяя эффективно обрабатывать синонимичные значения, опечатки и ошибки в поисковым запросе. Высокая эффективность модуля обеспечивается комбинированной работой различных алгоритмов поиска по сходству (fuzzy string search) и компьютерной лингвистики.

Преимущества модуля
| Установка и настройка модуля |
Требования к ПО В требованиях указана протестированная конфигурация. Если хостинг не удовлетворяет указанным требованиям, то напишите в нашу техническую поддержку, мы проверим совместимость модуля конкретно с Вашим ПО. |
Расширение поисковой выборки
Исходный поисковый индекс Bitrix искусственно расширяется: строится множество «ошибочных» слов, а также слов-синонимов (опционально). Таким образом, если пользователь введет поисковый запрос с ошибкой, который ранее попал в расширенный индекс, ему будет автоматически возвращена релевантная выдача. Данный режим не требует изменений стандартных компонентов.
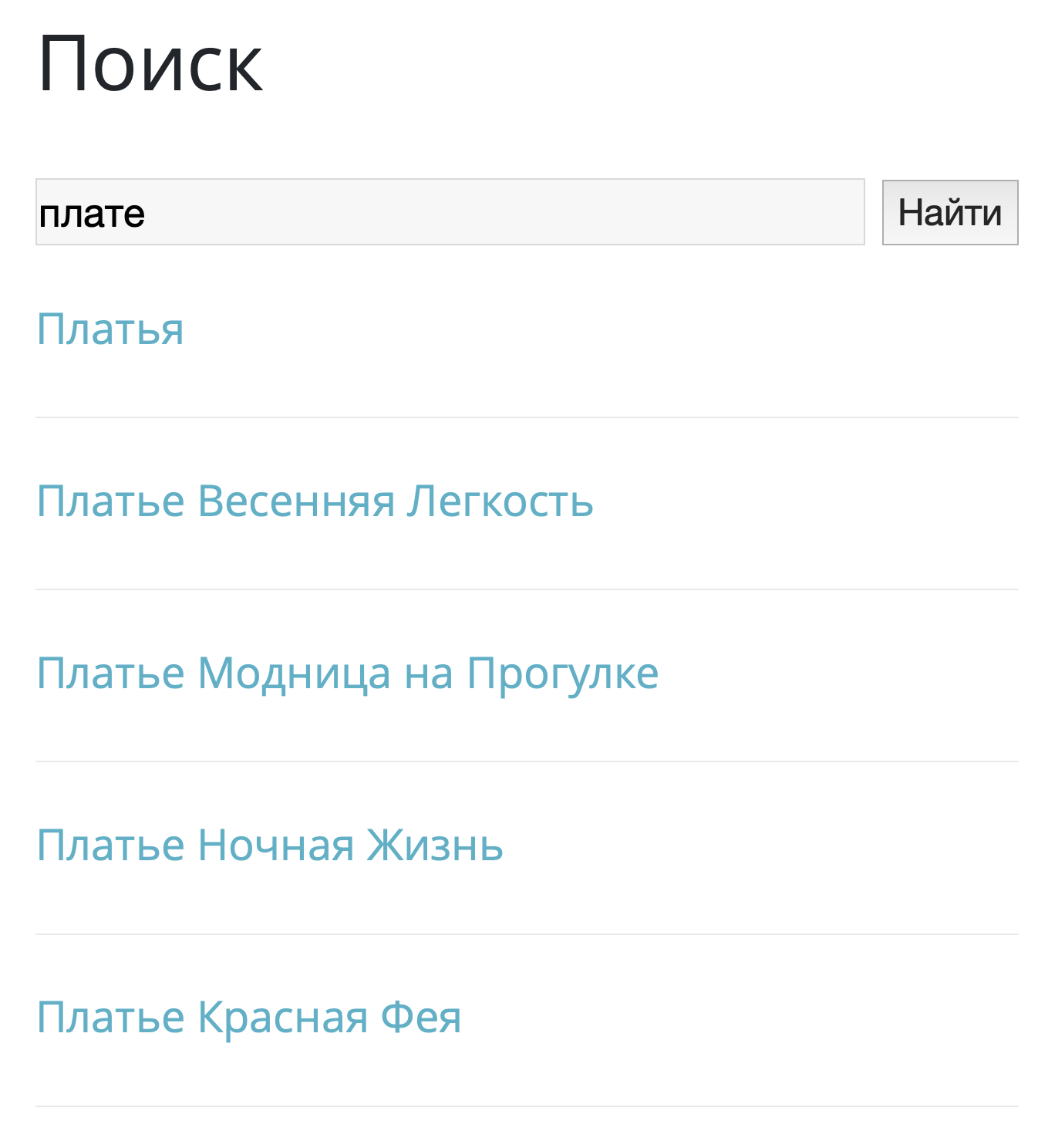
Ниже рассмотрен пример работы модуля с индексируемым словом «платье».

Поиск по сходству
|
При ошибочном поисковом запросе проиндексированные данные последовательно сравниваются с запрашиваемой строкой, ищутся максимально похожие на основании расстояния Левенштейна. Доступно сравнение на основании стемминга (морфологический основ) и metaphone (фонетического звучания). Для работы в режиме поиска по сходству, модуль использует как стандартный индекс Bitrix, так и собственные таблицы индексации. Данный режим требует замены стандартных компонентов bitrix:catalog.search, bitrix:search.title и bitrix:search.page на одноименные компоненты модуля. |
 |
Обработка поисковых запросов пользователей
При включенной опции «Собирать статистику по поисковым фразам» модуля «Поиск» будет производиться автоматический сбор информации по поисковым запросам пользователей. Ознакомиться с собранной статистикой можно на вкладке Настройки > Поиск > Статистика > Список фраз. Модуль «Нечеткий поиск» расширяет данный функционал, выбирая из статистики те запросы, для которых не нашлось ни одного совпадения. Фразы запросов разбиваются на отдельные слова, для слов находятся морфологические основы. При индексации данных на сайте выделенные морфологические основы будут сравниваться с основами индексируемых слов, близкие основы будут добавлены в индекс.
|
Пример работы Пользователь ввел поисковый запрос с опечаткой «фцтболка». Для данного запроса на сайте не было найдено совпадений, запрос попал специальную таблицу модуля «Нечеткий поиск». На сайте есть проиндексированное слово «футболка». Поскольку основа слова «футболка» близка к основе слова «фцтболка», происходит расширение поискового индекса. Теперь при запросе «фцтболка» пользователю будет возвращены данные, соответствующие поисковому индексу для «футболка».
|
Особенности
|

Словарь синонимов
Модуль «Нечеткий поиск» предоставляет удобный функционал для поиска по синонимам. Синонимы добавляются к поисковому индексу в случае, если морфологическая основа какого-либо слова из индекса совпадает с основой слова из таблицы синонимов.
Вместе с модулем поставляется обширный словарь синонимов, который пользователь может добавлять самостоятельно. Список синонимов смотрите в разделе Настройки > Нечеткий поиск > Словарь синонимов.
|
Пример работы Допустим, что в поисковый индекс попало слово «футболки», при этом в словаре активна запись для слова «футболка» с синонимами «рубашка, майка». Морфологические основы слов «футболки» и «футболка» совпали, поэтому слова «рубашка» и «майка» расширят поисковую выдачу для «футболки». |
Особенности
|
Часто задаваемые вопросы
|
Обрабатывает ли модуль ошибки раскладки клавиатуры? Да, обрабатывает. Данный функционал есть в стандартных компонентах bitrix (параметр «Включить автоопределение раскладки клавиатуры»), и он сохранен в компонентах модуля. Это позволяет, например, обработать ситуацию, когда пользователь ввел в строку поиска «gkfnmt» вместо «платье». Кроме того, в настройках модуля доступен режим сравнения по фонетическому сходству, что позволяет корректно обработать созвучные запросы разных языков, например «platie» вместо «платье». |
 |
Сегодня я вам расскажу как я улучшал стандартный функционал поиска на bitrix. Я покажу функции которые позволяют исправлять грамматические ошибки поисковых запросов, искать по части слова и по свойствам товаров.
Для начала я вам расскажу что я использовал для своей задачи.
- Во-первых, я сразу же отказался от стандартного метода поиска и поставил на свой хостинг Sphinx. Для своих сайтов я использую хостинг Beget, где в качестве дополнений можно установить данный модуль.
- Во-вторых, для исправления грамматических ошибок я буду использовать сервис Спеллер https://yandex.ru/dev/speller/ . Данный сервис получает текст с ошибкой через GET или POST запрос и возвращает исправленный текст в json формате.
Установка Sphinx сразу же решает проблему с индексацией по «части слова». Для того чтобы установить Sphinx необходимо перейти в Настройки->Настройки модулей->Поиск->Морфология и в поле «Полнотекстовый поиск с помощь Sphinx.
Конечно у меня не сразу получилось это сделать, но для решения своей проблемы я обратился в тех поддержку и он мне помогли.
Логика состоит в следующем — я буду делать первый запрос на получение товаров интернет магазина через поиск, если товары не приходят проверяют текст запроса на ошибки и делаю доп запрос.
Будут проверятся следующие виды ошибок:
- Неполные слова: див (диван), кров (кровать), бар (барная стойка)
- По свойству товара: желтый, синий
- По наличию буквы «Ё«.
На bitrix такая проблема что жёлтый и желтый это два разных ответа, первый возвращал 2 товара, второй больше - Грамматические ошибки: крАвать, жОлтый
- Сложные запросы: желтый диван, желтая кровать
- Сложные ошибочные запросы: жОлтая крАвать
- По названию: лофт
- Слова в английской транскрипции: ;tknsq, lbdfy
Теперь давайте рассмотрим сам код. Код у нас будет только на языке PHP.
Первым делом я напишу класс в котором будут записаны основные методы для обработки поисковых запросов.
Сразу замечу что фраза для поискового запроса хранится в $_REQUEST[«q»] поэтому перед каждым новым запросом я буду записывать новую поисковую строку именно в эту переменную.
class DopSearchClass {
/* ДЕЛАЕМ ЗАПРОС НА ПРОВЕРКУ ГРАММАТИКИ */
public function checkValueSearch($textSearch) {
$textQuery = urlencode($textSearch);
$url = "https://speller.yandex.net/services/spellservice.json/checkText?text=".$textQuery;
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, true);
curl_setopt($ch, CURLOPT_HEADER, true);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
$resultCheck = curl_exec($curl);
$resultCheck = json_decode($resultCheck, true);
if($resultCheck) {
/* массив в который будут записываться обработанные значения */
$listCurrentText = array();
/* если у нас только одно ошибочное слово */
if(count($resultCheck) == 1) {
/* записываем вариант ошибки */
$falseText = $resultCheck[0]["word"];
/* преобразуем ассоциативный массив в обычный */
$arrValidWord = array_values($resultCheck[0]["s"]);
/* удаляем однокоренные слова */
$validWord = $this->clearBySixFirstLetter($arrValidWord);
foreach($validWord as $word) {
$newTextSearch = str_replace($falseText, $word, $textSearch);
array_push($listCurrentText, $newTextSearch);
}
}
/* если несколько ошибочных слов */
else if(count($resultCheck) > 1) {
foreach($resultCheck as $arrWord) {
$falseText = $arrWord["word"];
$textSearch = str_replace($falseText, $arrWord["s"][0], $textSearch);
}
array_push($listCurrentText, $textSearch);
}
return $listCurrentText;
}
}
/* УДАЛЯЕМ ОДНОКОРЕННЫЕ СЛОВА */
public function clearBySixFirstLetter($array) {
/* записываем корни слов */
$has = [];
return array_filter(
$array,
function ($word) use (&$has) {
$sixLetters = mb_substr($word, 0, 6);
if (!in_array($sixLetters, $has)) {
array_push($has, $sixLetters);
return true;
}
return false;
}
);
}
/* МЕНЯЕМ "Ё" НА "Е" */
public function alternateSymbol($str) {
$str = strtolower($str);
return str_replace("ё", "е", $str);
}
}
Давайте я немного расскажу по каждому методу…
- checkValueSearch — делает запрос на проверку грамматики. Если есть ошибка в одном слове, то мы берём все варианты правильного значения и в дальнейшем делаем перезапрос с новыми словами. Если у нас НЕСКОЛЬКО ОШИБОЧНЫХ СЛОВ, то для упрощения с сделал так чтобы доставался 1 правильный вариант по каждому слову и формировалась новая строка запроса. Для улучшения вы можете составить комбинации из всех значений и пройтись по всем, мне же достаточно и этого!
- clearBySixFirstLetter — удаляет однокоренные слова из полученных значений от Яндекс Спеллер. Дело в том что в «битриксовском» поиске уже есть возможность использовать морфологический анализ для получения результата, поэтому однокоренные слова будут возвращать одинаковый результат.
- alternateSymbol — ищет в строке запроса букву «Ё» и если она есть, то добавляет значения с вариантом «Е». Получается что слово «жёлтый» вернёт значения для себя и для слова «желтый»
Ниже в этом же файле я запускаю работу основного скрипта.
Для начала я просто делаю запрос и проверяю есть ли результат. Проводить все доп запросы я буду только если ответ пустой или имеет букву «Ё» в слове.
/* вначале делаем поисковой запрос без преобразования */
$searchResult = $APPLICATION->IncludeComponent(
"bitrix:search.page",
"ajax",
array(
"AJAX_MODE" => "N",
"AJAX_OPTION_ADDITIONAL" => "",
"AJAX_OPTION_HISTORY" => "N",
"AJAX_OPTION_JUMP" => "N",
"AJAX_OPTION_STYLE" => "N",
"CACHE_TIME" => "3600",
"CACHE_TYPE" => "A",
"CHECK_DATES" => "Y",
"DEFAULT_SORT" => "rank",
"DISPLAY_BOTTOM_PAGER" => "Y",
"DISPLAY_TOP_PAGER" => "N",
"FILTER_NAME" => "",
"PAGER_SHOW_ALWAYS" => "N",
"PAGER_TEMPLATE" => "",
"PAGER_TITLE" => "Результаты поиска",
"PAGE_RESULT_COUNT" => "500",
"RESTART" => "Y",
"SHOW_WHEN" => "N",
"SHOW_WHERE" => "N",
"USE_LANGUAGE_GUESS" => "N",
"USE_SUGGEST" => "N",
"USE_TITLE_RANK" => "Y",
"arrFILTER" => array(
0 => "iblock_catalog",
),
"arrWHERE" => array(
0 => "iblock_catalog",
),
"COMPONENT_TEMPLATE" => "ajax",
"arrFILTER_iblock_catalog" => array(
0 => "5",
)
),
false
);
Если результат есть, то попробуем поискать букву Ё в словах. Если Ё есть то делаем новый запрос и сливаем массивы.
/* если товары есть, то проверяем значение запроса на наличие буквы "Ё" */
if(count($searchResult) > 0) {
if(strpos($_REQUEST["q"], "ё") !== false) {
$newSearchCheck = new DopSearchClass();
$_REQUEST["q"] = $newSearchCheck->alternateSymbol($_REQUEST["q"]);
/* в нижний регистр */
$str = strtolower($_REQUEST["q"]);
$_REQUEST["q"] = str_replace("ё", "е", $str);
$thisSearchResult = $APPLICATION->IncludeComponent(
"bitrix:search.page",
"ajax",
array(
"AJAX_MODE" => "N",
"AJAX_OPTION_ADDITIONAL" => "",
"AJAX_OPTION_HISTORY" => "N",
"AJAX_OPTION_JUMP" => "N",
"AJAX_OPTION_STYLE" => "N",
"CACHE_TIME" => "3600",
"CACHE_TYPE" => "A",
"CHECK_DATES" => "Y",
"DEFAULT_SORT" => "rank",
"DISPLAY_BOTTOM_PAGER" => "Y",
"DISPLAY_TOP_PAGER" => "N",
"FILTER_NAME" => "",
"PAGER_SHOW_ALWAYS" => "N",
"PAGER_TEMPLATE" => "",
"PAGER_TITLE" => "Результаты поиска",
"PAGE_RESULT_COUNT" => "500",
"RESTART" => "Y",
"SHOW_WHEN" => "N",
"SHOW_WHERE" => "N",
"USE_LANGUAGE_GUESS" => "N",
"USE_SUGGEST" => "N",
"USE_TITLE_RANK" => "Y",
"arrFILTER" => array(
0 => "iblock_catalog",
),
"arrWHERE" => array(
0 => "iblock_catalog",
),
"COMPONENT_TEMPLATE" => "ajax",
"arrFILTER_iblock_catalog" => array(
0 => "5",
)
),
false
);
/* если результат есть, то сливаем его с полным результатом */
if($thisSearchResult) {
$searchResult = array_merge($searchResult, $thisSearchResult);
}
}
}Если первый запрос не вернул результат то вначале опять проверяем запрос на букву «Ё», но только в этот раз мы проверяем когда пришёл пустой ответ, а потом если опять результатов не будет то делаем запрос на проверку грамматических ошибок.
/* если пришёл пустой результат */
else if(count($searchResult) < 1) {
$newSearchCheck = new DopSearchClass();
/* если ошибка только в букве "Ё" */
if(strpos($_REQUEST["q"], "ё") !== false) {
$_REQUEST["q"] = $newSearchCheck->alternateSymbol($_REQUEST["q"]);
$str = strtolower($_REQUEST["q"]);
$_REQUEST["q"] = str_replace("ё", "е", $str);
$thisSearchResult = $APPLICATION->IncludeComponent(
"bitrix:search.page",
"ajax",
array(
"AJAX_MODE" => "N",
"AJAX_OPTION_ADDITIONAL" => "",
"AJAX_OPTION_HISTORY" => "N",
"AJAX_OPTION_JUMP" => "N",
"AJAX_OPTION_STYLE" => "N",
"CACHE_TIME" => "3600",
"CACHE_TYPE" => "A",
"CHECK_DATES" => "Y",
"DEFAULT_SORT" => "rank",
"DISPLAY_BOTTOM_PAGER" => "Y",
"DISPLAY_TOP_PAGER" => "N",
"FILTER_NAME" => "",
"PAGER_SHOW_ALWAYS" => "N",
"PAGER_TEMPLATE" => "",
"PAGER_TITLE" => "Результаты поиска",
"PAGE_RESULT_COUNT" => "500",
"RESTART" => "Y",
"SHOW_WHEN" => "N",
"SHOW_WHERE" => "N",
"USE_LANGUAGE_GUESS" => "N",
"USE_SUGGEST" => "N",
"USE_TITLE_RANK" => "Y",
"arrFILTER" => array(
0 => "iblock_catalog",
),
"arrWHERE" => array(
0 => "iblock_catalog",
),
"COMPONENT_TEMPLATE" => "ajax",
"arrFILTER_iblock_catalog" => array(
0 => "5",
)
),
false
);
/* если результат есть, то сливаем его с полным результатом */
if($thisSearchResult) {
$searchResult = array_merge($searchResult, $thisSearchResult);
}
}
/* если исправление буквы "Ё" не помогло и опять вернулся пустой ответ */
if(count($searchResult) < 1) {
/* проверям грамматику */
$arrValidWord = $newSearchCheck->checkValueSearch($_REQUEST["q"]);
/* если такого слова не существует */
if(count($arrValidWord) == 0) {
$errorMessageSearch = "К сожалению по данному запросу мы не чего не нашли!";
}
else if(count($arrValidWord) > 0) {
/* делаем запрос по каждому варианту ИСПРАВЛЕННОГО слова */
foreach($arrValidWord as $word) {
$_REQUEST["q"] = $word;
$thisSearchResult = $APPLICATION->IncludeComponent(
"bitrix:search.page",
"ajax",
array(
"AJAX_MODE" => "N",
"AJAX_OPTION_ADDITIONAL" => "",
"AJAX_OPTION_HISTORY" => "N",
"AJAX_OPTION_JUMP" => "N",
"AJAX_OPTION_STYLE" => "N",
"CACHE_TIME" => "3600",
"CACHE_TYPE" => "A",
"CHECK_DATES" => "Y",
"DEFAULT_SORT" => "rank",
"DISPLAY_BOTTOM_PAGER" => "Y",
"DISPLAY_TOP_PAGER" => "N",
"FILTER_NAME" => "",
"PAGER_SHOW_ALWAYS" => "N",
"PAGER_TEMPLATE" => "",
"PAGER_TITLE" => "Результаты поиска",
"PAGE_RESULT_COUNT" => "500",
"RESTART" => "Y",
"SHOW_WHEN" => "N",
"SHOW_WHERE" => "N",
"USE_LANGUAGE_GUESS" => "N",
"USE_SUGGEST" => "N",
"USE_TITLE_RANK" => "Y",
"arrFILTER" => array(
0 => "iblock_catalog",
),
"arrWHERE" => array(
0 => "iblock_catalog",
),
"COMPONENT_TEMPLATE" => "ajax",
"arrFILTER_iblock_catalog" => array(
0 => "5",
)
),
false
);
/* если результат есть, то сливаем его с полным результатом */
if($thisSearchResult) {
$searchResult = array_merge($searchResult, $thisSearchResult);
}
/* проверяем слово запроса н наличие буквы "Ё" и заменяем её на "Е" */
if(strpos($word, "ё") !== false) {
$_REQUEST["q"] = $newSearchCheck->alternateSymbol($word);
$thisSearchResult = $APPLICATION->IncludeComponent(
"bitrix:search.page",
"ajax",
array(
"AJAX_MODE" => "N",
"AJAX_OPTION_ADDITIONAL" => "",
"AJAX_OPTION_HISTORY" => "N",
"AJAX_OPTION_JUMP" => "N",
"AJAX_OPTION_STYLE" => "N",
"CACHE_TIME" => "3600",
"CACHE_TYPE" => "A",
"CHECK_DATES" => "Y",
"DEFAULT_SORT" => "rank",
"DISPLAY_BOTTOM_PAGER" => "Y",
"DISPLAY_TOP_PAGER" => "N",
"FILTER_NAME" => "",
"PAGER_SHOW_ALWAYS" => "N",
"PAGER_TEMPLATE" => "",
"PAGER_TITLE" => "Результаты поиска",
"PAGE_RESULT_COUNT" => "500",
"RESTART" => "Y",
"SHOW_WHEN" => "N",
"SHOW_WHERE" => "N",
"USE_LANGUAGE_GUESS" => "N",
"USE_SUGGEST" => "N",
"USE_TITLE_RANK" => "Y",
"arrFILTER" => array(
0 => "iblock_catalog",
),
"arrWHERE" => array(
0 => "iblock_catalog",
),
"COMPONENT_TEMPLATE" => "ajax",
"arrFILTER_iblock_catalog" => array(
0 => "5",
)
),
false
);
/* если результат есть, то сливаем его с полным результатом */
if($thisSearchResult) {
$searchResult = array_merge($searchResult, $thisSearchResult);
}
}
}
}
}
}После использования данного способа у вас не получится сделать полностью идеальный поиск, так как здесь есть ещё над чем поработать, но в любом случае данные преобразования гораздо улучшат ваш поиск.
Я понимаю что данный способ использует в своей работе запросы на компонент поиска через цикл, чего я категорически не рекомендую делать, так как это сильно нагружает сайт, но в данном случае я не нашёл другого выхода как можно добиться результата.
Не смотря на это вы всегда можете записать полученные значения в кэш и вытаскивать их при повторном запросе. Если у меня будут время, я обязательно поделюсь тем как это можно сделать используя базовый функционал битрикса.
«1С Битрикс» отлично подходит для интернет-магазинов, сайтов услуг, контент-проектов и корпоративных ресурсов. Функциональность и простота настроек — главные преимущества CMS. Между тем, SEO для сайтов на Битриксе имеет некоторые особенности, которые нужно учитывать, чтобы получить бесплатный трафик из поисковых систем.
Общий пошаговый алгоритм оптимизации:
- Технические настройки: robots.txt, sitemap.xml, настройка ЧПУ, «хлебных крошек», контроль за скоростью сайта и пр.
- Оптимизация мета-тегов: шаблонные решения и уникальные метаданные.
- Установка дополнительных модулей для решения точечных задач по оптимизации.
Первые два пункта можно выполнить на любом сайте, который работает на Битриксе, т. к. функционал встроен в SEO-модуль и присутствует в любой версии CMS, даже в редакции «Старт». Для более глубоких задач предусмотрены отдельные модули — платные и бесплатные.
Важно! В этом алгоритме прописаны основные особенности и возможности Битрикса в разрезе SEO, но это далеко не полный список работ по продвижению сайта.

Базовые инструменты для технической оптимизации
Настройка robots.txt
Robots.txt — значимый текстовый файл, который указывает поисковым системам на правила индексации сайта:
- запрещены или разрешены в поиске определенные страницы и разделы;
- каким должен быть минимальный период времени между окончанием загрузки одного файла и началом следующего;
-
присутствуют ли URL с параметрами, которые не нужно индексировать;
- какая xml карта актуальна для данного сайта.
В Битриксе настройка robots.txt реализована максимально просто и удобно. В административном разделе необходимо пройти путь «Маркетинг» — «Поисковая оптимизация» — «Настройка robots.txt»:
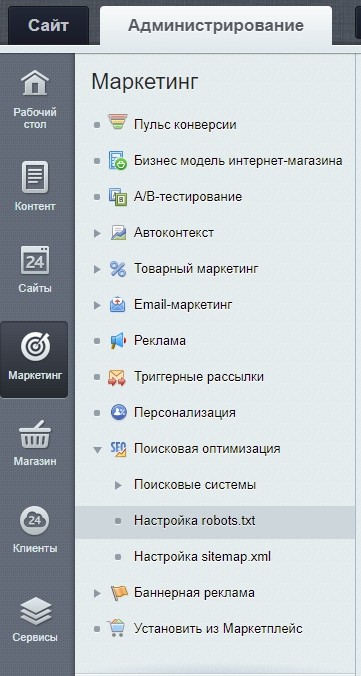
Редактирование robots.txt в Битриксе
Система позволяет задать правила индексации как отдельно для Google и Яндекса, так и для обеих поисковых систем разом. Весомый плюс: если вы не знакомы с синтаксисом robots.txt, можно воспользоваться готовыми кнопками «Запретить файл», «Главное зеркало» и пр. Нужно прописать условия действия, а система сама добавит необходимую директиву.
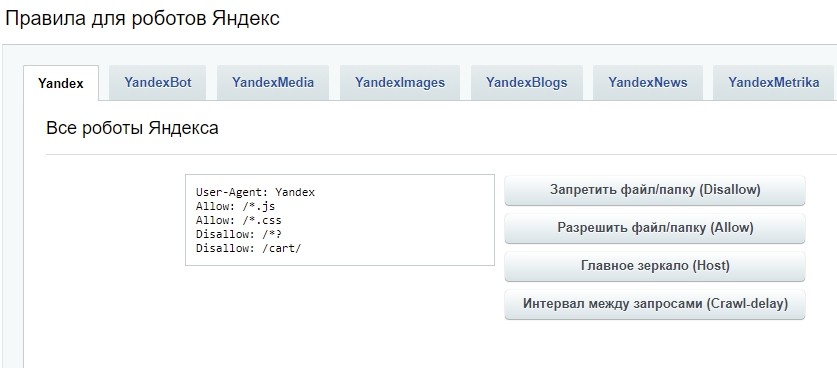
Редактирование robots.txt в Битриксе для роботов Яндекс
Генерация Sitemap.xml
Sitemap.xml содержит данные о страницах и структуре сайта, — эта информация необходима поисковым роботам. Также в sitemap.xml можно указывать приоритет страниц, частоту и дату их последнего обновления.
Чтобы сформировать карту сайта в Битриксе, нужно открыть соответствующий раздел: «Маркетинг» — «Поисковая оптимизация» — «Настройка sitemap.xml», затем указать протокол, домен и актуальный адрес будущего файла xml. После этого необходимо настроить файловую структуру (опираясь либо на файлы и папки, либо на логическую структуру сайта) и инфоблоки.
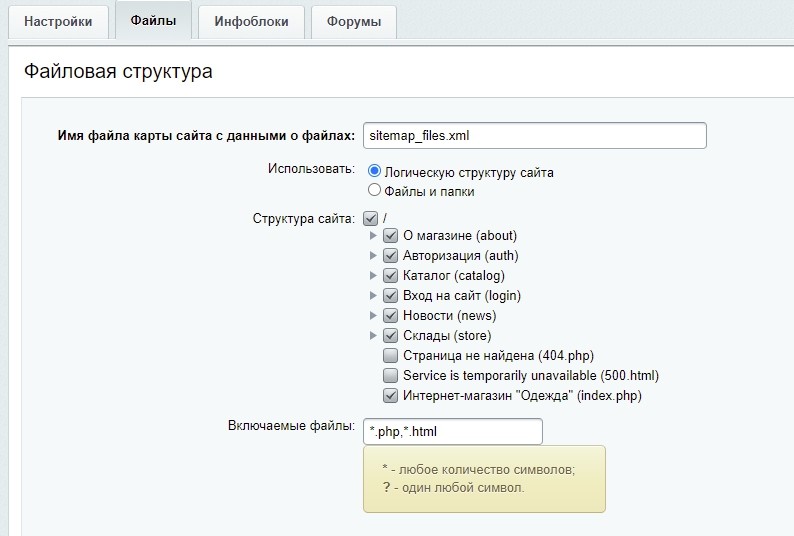
Редактирование sitemap.xml в Битриксе
Когда все настройки выполнены, нужно “Сохранить и запустить” файл.
Настройка ЧПУ
Человекопонятные URL (ЧПУ) — один из главных пунктов SEO оптимизации.
В Битриксе они задаются через редактирование компонентов. В «Публичном разделе» необходимо перейти в «Режим правки» и вызвать настройки компонента. Затем нужно выбрать «Управление адресами страниц» и задать правила по логике формирования ЧПУ.
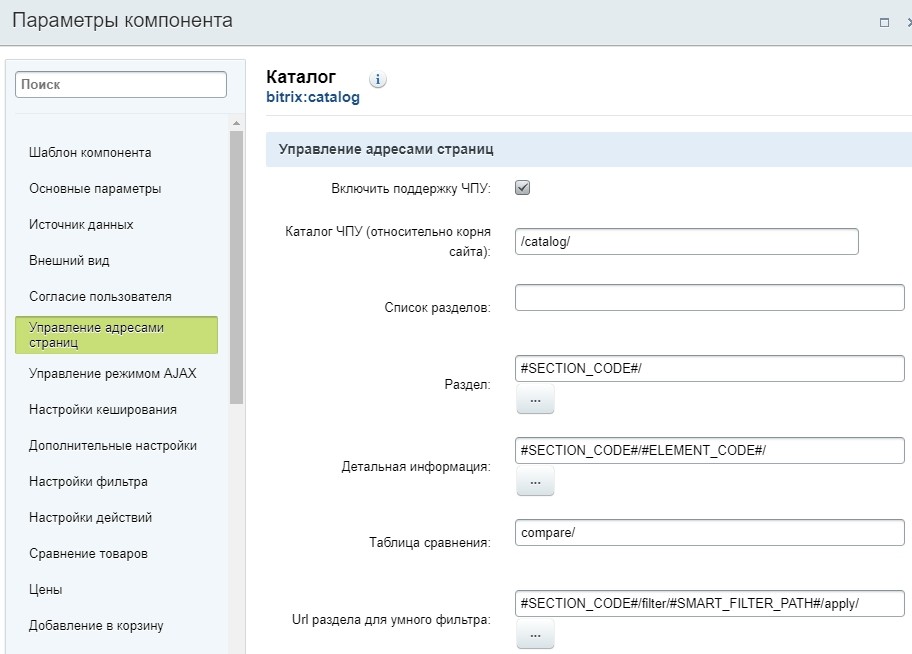
Правила настройки ЧПУ
После редактирования настроек компонента, необходимо синхронизировать данные с параметрами соответствующего инфоблока. Коды, заданные в компоненте каталога, должны совпадать с кодами в строках URL страницы инфоблока, URL страницы раздела и URL страницы детального просмотра.
Цепочка навигации (Хлебные крошки)
Так называемые хлебные крошки — незаменимый инструмент навигации, особенно важный для крупных интернет-магазинов. Преимущество Битрикса в том, что необходимый компонент выводится по умолчанию на всех страницах сайта, поэтому сложных технических настроек не требуется.
Однако при желании можно скорректировать названия разделов, которые отображаются в цепочке навигации.
Для этого через «Публичный раздел» нужно перейти в «Свойства раздела»:
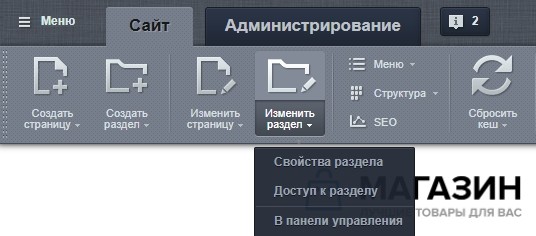
Редактирование Хлебных крошек
И затем отредактировать «Заголовок»:
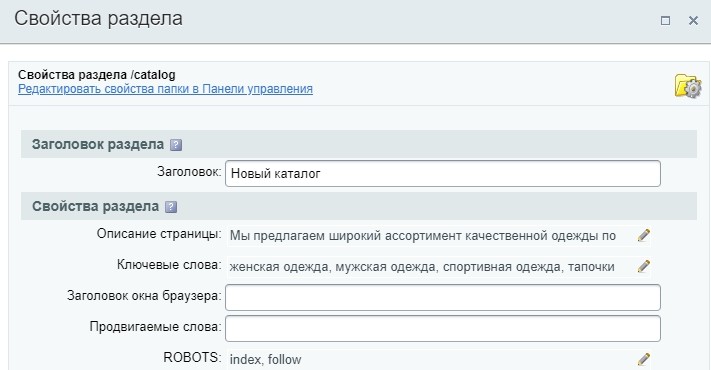
Редактирование Навигационной цепочки
Результат:
![]()
Отображение ХК в Битриксе
Производительность сайта
Скорость загрузки — один из важнейших факторов продвижения. Битрикс позволяет мониторить производительность сайта, понять, как ведет себя ресурс по мере роста нагрузки и необходимы ли доработки.
Для мониторинга производительности в «Настройки» — «Производительность» — «Панель производительности»:
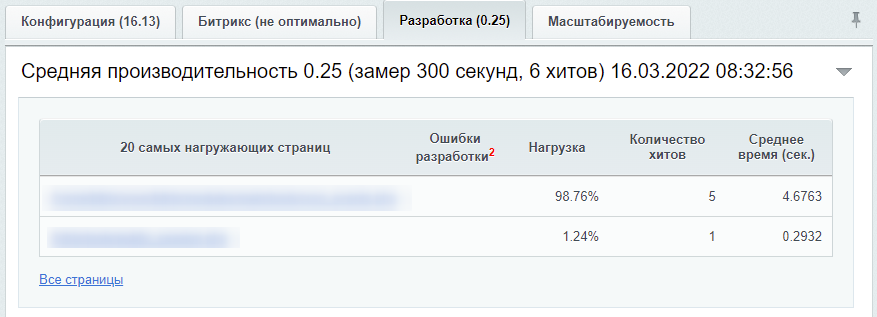
Как посмотреть производительность сайта на Битриксе
Как правило, стандартным небольшим сайтам на Битриксе не требуются дополнительные работы по повышению скорости загрузки страниц. Однако данные работы могут быть актуальны для крупных интернет-проектов или кастомных разработок.
Тогда на помощь придут:
- Переопределение настроек кеширования. Кеширование — функция, которая связана с повторным воспроизведением информации без обращения к базам данных. Подключение технологии кеширования memcached.
- Оптимизация JS и CSS файлов для экономии времени загрузки.
- Технология «Композитный сайт», позволяющая подгружать контент по мере просмотра информации пользователем.
- Оптимизация конфигурации серверного окружения.
- Работа с замечаниями Pagespeed insights.
- Сокращения физического веса страниц путем оптимизации изображений, ресайз и сжатие.
Все способы ускорения загрузки сайта требуют глубоких знаний специфики и технологий Битрикса. Помочь в настройках сможет опытный разработчик: задачи подобного типа, как правило, выполняются в рамках техподдержки сайта.
Заказать техподдержку и ознакомиться с тарифами на услугу вы можете в разделе «Техническая поддержка сайтов».
Title и мета-теги, например, description, оказывают прямое влияние на позиции сайта в поисковой выдачи. Чтобы SEO-продвижение было максимально эффективным, заполнению этой информации нужно уделить особое внимание. В Битриксе предусмотрен отдельный функционал, который выглядит следующим образом:
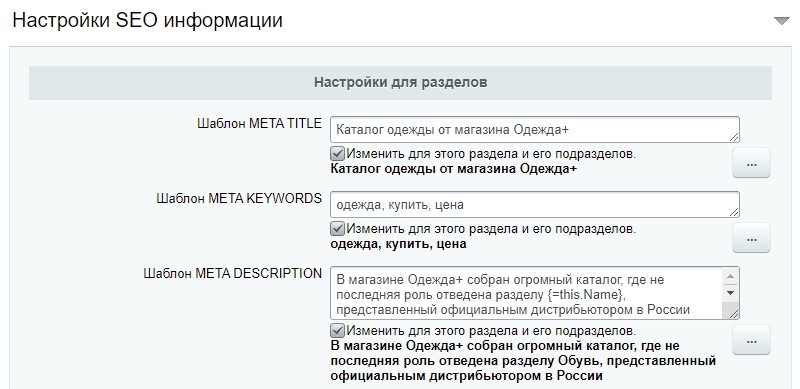
Заполнение метаданных в Битриксе
В соответствующие полях необходимо прописать оптимизированные метаданные и заголовки.
Для удобства и ускорения процесса, можно использовать шаблоны. Особенно это актуально для крупных проектов с множеством категорий и товаров. Битрикс — достаточно гибкая система, поэтому с ее помощью можно решить практически любые SEO задачи, связанные с метаданными, например:
- Настройка шаблонных метаданных для всех товаров одновременно.
- Настройка разных шаблонов для разных разделов и подразделов.
- Присвоение уникальных заголовков и мета определенным разделам или товарам.
При этом стоит учитывать особенность СMS: наследование SEO-данных определяется пирамидальным образом, т. е. подразделу присваиваются те же мета, что и родительскому разделу. Избежать дублей можно двумя способами:
-
Использовать переменные

- Прописывать метаданные, начиная с подраздела с самым высоким уровнем вложенности, постепенно продвигаясь к верхнему родительскому разделу.

Дополнительные модули для Битрикса
Помимо стандартных “решений из коробки” в Битриксе можно устанавливать модули от сторонних разработчиков или разрабатывать свои. Расширенный функционал позволяет решать самые разные задачи: от упрощенной настройки редиректов до интеграции с крупными сервисами типа СберМаркета, Яндекс.Маркета, Алиэкспресс.
Как узнать, нужен ли вашему сайту дополнительный модуль? Закажите обратный звонок, опишите свой проект и желаемые результаты — наш специалист проконсультирует вас.
Ниже представлены самые популярные разновидности модулей Битрикса, которые будут полезны с точки зрения SEO.
Настройка Турбо страниц
Для интернет-магазинов и контентных проектов используются разные модули этого типа, среди них есть платные и бесплатные. Установка подобного решения позволит сформировать xml-фид, который легко будет загрузить в Яндекс.Вебмастер и настроить Турбо страницы.
Например, один из таких модулей «Яндекс.Маркет для продавцов» — мощный бесплатный официальный инструмент от Яндекса. Позволяет настраивать интеграцию с маркетплейсом, XML-фиды разных форматов для Турбо страниц.
SEO для умного фильтра
Основной функционал: формирование уникальных метаданных для страниц умного фильтра. За счет такой оптимизации можно будет привлекать на сайт значительный низкочастотный трафик.
Подобный модуль может использоваться как самостоятельный или входить в состав более сложных SEO модулей, в которых кроме прочего, могут быть предусмотрены другие SEO настройки.
Нечеткий поиск: умный поиск с учетом синонимов
Улучшить поведенческие факторы поможет качественный поиск по сайту, учитывающий изменения словоформ, опечатки, поиск по синонимам. Иными словами, это расширенный и улучшенный функционал встроенного модуля «Поиск» от Битрикса. Решение будет актуально для крупных интернет-проектов, например, новостных сайтов или интернет-магазинов.
Отложенная загрузка изображения и/или YouTube видео
Это своего рода «ленивая» загрузка: фото или видео не начинает загружаться, пока пользователь не доскроллил страницу до нужного места. В результате ускоряется отображение страницы сайта, что является хорошим сигналом для поисковой системы.
Мультирегиональность
Модуль подходит компаниям, которые работают в нескольких регионах. Позволяет выстроить систему поддоменов, и для каждого региона отображает актуальную информацию, например, остаток товара, цены, контакты и пр.
Что нужно сделать перед установкой любого дополнительного модуля:
- Посмотреть подходящие редакции (так, определенные модули могут не подходить для «Старта»).
- Узнать, входит ли в стоимость техподдержка.
- Проверить, есть ли понятная документация.
- Познакомиться с отзывами.
- Попробовать тестовую версию, если она есть.
Продвижение сайта на Битриксе: вопросы и ответы
Дает ли Битрикс преимущества в ранжировании?
Нет достоверных исследований, что сам факт наличия определенной CMS положительно сказывается на продвижении. При этом удобство работы с системой, быстрая скорость загрузки сайта значительно облегчают SEO-продвижение.
Нужно ли для оптимизации привлекать разработчика?
С оптимизацией сайта на Битриксе справится контент-менеджер или seo-специалист, если речь идет о базовых настройках и размещении метатегов. При этом для установки модулей, а также для кастомных доработок рекомендуется привлекать разработчика.
Какую редакцию выбрать?
Самый широкий функционал представлен в редакциях «Бизнес» и «Энтерпрайз», однако он не всегда нужен на небольших проектах. Чтобы разобраться в особенностях и возможностях Битрикса, выбрать нужную редакцию, звоните 8 (800) 600-60-74.
Резюме
Битрикс — удобная, гибкая система, позволяющая выполнять SEO для проектов любых масштабов.
Сложности могут возникнуть при редактировании инфоблоков или компонентов — зачастую “схожие по смыслу” настройки находятся в разных местах. Однако такая специфика обусловлена логикой системы и оправдана высокой безопасностью и производительностью.
SEO-продвижение сайта на Битриксе — многоэтапный сложный процесс, который при грамотном подходе принесет отличные результаты и позволит привлечь новых клиентов. Нет времени разбираться в тонкостях CMS? Закажите сайт на Битриксе под ключ! Мы подберем оптимальную стратегию, исходя из целей и специфики вашего проекта.

Первое что нужно сделать при разработке поисковых, диалоговых и прочих систем, основанных на natural language processing — это научиться разбирать тексты пользовательских запросов и находить в них сущности рабочей модели. Задача нахождения стандартных сущностей (geo, date, money и т.д.) в целом уже решена, остается лишь выбрать подходящий NER компонент и воспользоваться его функционалом. Если же вам нужно найти элемент, характерный для вашей конкретной модели или вы нуждаетесь в улучшенном качестве поиска стандартного элемента, придется создать свой собственный NER компонент или обучить какой-то уже существующий под свои цели.
Если вы работаете с системами вроде Alexa или Google Dialogflow — процесс обучения сводится к созданию простейшей конфигурации. Для каждой сущности модели вы должны создать список синонимов. Далее в дело вступают нейронные сети. Это быстро, просто, очень удобно, все заработает сразу. Из минусов — отсутствует контроль за настройками нейронных сетей, а также одна общая для данных систем проблема — вероятностный характер поиска. Все эти минусы могут быть совершенно не важны для вашей модели, особенно если в ней ищется одна-две принципиально отличающиеся друг от друга сущности. Но если элементов модели достаточно много, а особенно если они в чем-то пересекаются, проблема становится более значимой.
Если вы проектируете собственную систему, обучаете и настраиваете поисковые компоненты, например от Apache OpenNlp, Stanford NLP, Google Language API, Spacy или Apache NlpCraft для поиска собственных элементов, забот, разумеется, несколько больше, но и контроль над такой системой заметно выше.
Ниже поговорим о том, как нейронные сети используются при поиске сущностей в проекте Apache NlpCraft. Для начала вкратце опишем все возможности поиска в системе.
Поиск пользовательских сущностей в Apache NlpCraft
При построении систем на базе Apache NlpCraft вы можете использовать следующие возможности по поиску собственных элементов:
- Встроенные компоненты поиска, основанные на конфигурации синонимов элементов. Пример описания элементов моделей, основанных на синонимах, Synonym DSL т.д. приведены в ознакомительной статье о проекте.
- Использование любого из вышеупомянутых внешних компонентов, интеграция с ними уже предусмотрена, вы просто подключаете их в конфигурации.
- Применение составных сущностей. Суть — в возможности построения новых NER компонентов на основе уже существующих. Подробнее — тут.
- Самый низкоуровневый вариант — программирование и подключение в систему своего собственного парсера. Данная задача сводится к имплементации интерфейса и добавлении его в систему через IoC. На входе реализуемого компонента есть все для написания логики поиска сущностей в запросе: сам запрос и его NLP представление, модель и все уже найденные в тексте запроса другими компонентами сущности. Эта имплементация — место для подключения нейросетей, использования собственных алгоритмов, интеграции с любыми внешними системами и т.д., то есть точка полного контроля над поиском.
Первый подход, работающий на основе настройки синонимов, не требующий ни программирования, ни текстовых корпусов для обучения модели, является самым простым, универсальным и быстрым для разработки.
Ниже представлен фрагмент конфигурации модели “умный дом” (подробнее о макросах и synonym DSL можно прочесть по ссылке).
macros:
- name: "<ACTION>"
macro: "{turn|switch|dial|control|let|set|get|put}"
- name: "<ENTIRE_OPT>"
macro: "{entire|full|whole|total|*}"
- name: "<LIGHT>"
macro: "{all|*} {it|them|light|illumination|lamp|lamplight}"
...
- id: "ls:on"
description: "Light switch ON action."
synonyms:
- "<ACTION> {on|up|*} <LIGHT> {on|up|*}"
- "<LIGHT> {on|up}"
Элемент “ls:on” описан очень компактно, при этом данное описание содержит в себе более 3000 синонимов. Вот их малая часть: “set lamp“, “light on“, “control lamp“, “put them“, “switch it all“… Синонимы конфигурируются в весьма сжатом виде, при этом вполне читаемы.
Несколько замечаний:
- Разумеется, при работе с поиском по синонимам учитываются начальные формы слов (леммы, стеммы), стоп-слова текста запроса, конфигурируется поддержка прерывистости многословных синонимов и т.д. и т.п.
- Часть сгенерированных синонимов не будет иметь практического смысла, это вполне ожидаемая плата за компактность записи. Если использование памяти станет узким местом (тут речь должна идти о миллионах и более вариантов синонимов на сущность), стоит задуматься об оптимизации. Вы получите все необходимые warnings при старте системы.
Итак вы полностью управляете процессом поиска ваших элементов в тексте запросов, этот процесс является детерминированным, то есть в итоге отлаживаемым, контролируемым, и имеет возможности для последовательного улучшения. Теперь вам нужно лишь аккуратно составить достаточный список синонимов. Здесь вступает в игру человеческий фактор. На этапе старта проекта можно ограничиться лишь несколькими основными синонимами на элемент, достаточно добавить буквально одно-два слова, все будет работать, но в итоге конечно хочется поддержать максимально полный список синонимов для обеспечения наиболее качественного процесса распознавания.
Что может подсказать нам недостающие синонимы в конфигурации, ведь от ее полноты напрямую будет зависеть качество нашей системы?
Расширение списка синонимов
Первое очевидное направление — это в ручном режиме отслеживать логи и анализировать неотвеченные вопросы.
Второе — посмотреть в словаре синонимов, что может быть достаточно полезно для очевидных случаев. Один их самых известных словарей — wordnet.

Работа в ручном режиме может принести определенную пользу, но процесс поиска и конфигурирования дополнительных синонимов элементов здесь явно не стоит автоматизировать.
Помимо этого, разработчики Apache NlpCraft добавили в проект инструмент sugsyn, предлагающий, в процессе использования, дополнительные синонимы для элементов модели.
Компонент sugsyn работает стандартным образом через REST API, взаимодействуя с дополнительным сервером, поставляемым в бинарных релизах — ContextWordServer.
Описание ContextWordServer
ContextWordServer позволяет искать синонимы к слову в заданном контексте. В качестве запроса пользователь передает предложение с помеченным словом, к которому нужно подобрать синонимы, а сервер, используя выбранную модель, возвращает список наиболее подходящих слов заменителей.
Изначально в качестве базовой модели был использован word2vec (skip-gram модель), позволяющий строить векторные представления слов (или эмбеддинги). Идея заключалась в том, чтобы посчитать эмбеддинги слов и основываясь на полученном векторном пространстве отобрать слова, находящиеся ближе всего к целевому.
В целом данный подход работал удовлетворительно, но контекст слов учитывался недостаточно хорошо, даже при больших значениях N для n-граммов. Тогда было предложено использование Bert для решения задачи masked language modeling (поиск наиболее подходящих слов, которые можно подставить вместо маски в предложение). В предложении, которое передавал пользователь, маскировалось целевое слово, и выдача Bert являлась ответом. Недостатком использования одного лишь Bert также было получение не совсем удовлетворительного списка слов, подходящих по контексту использования, но не являющихся близкими синонимами заданного.
Решением этой проблемы стало комбинирование двух методов. Теперь, выдача Bert отфильтровывается, выкидывая слова с векторным расстоянием до целевого слова выше определенного порога.
Далее, по результатам экспериментов, word2vec был заменен на fasttext (логический наследник word2vec), показывающий лучшие результаты. Была использована готовая модель, предобученная на статьях из Wikipedia, а модель Bert была заменена на улучшенную модель — Roberta, смотри ссылку на предобученную модель.
Итоговый алгоритм не требует использования именно fasttext или Roberta в качестве составных частей. Обе подсистемы могут быть заменены альтернативными, способными решить схожие задачи. Кроме того, для лучшего результата предобученной модели могут быть fine-tuned, либо обучены с нуля.
Описание инструмента sugsyn
Работа с sugsyn, удобней всего осуществляется через CLI. Требуется скачать последнюю версию бинарного релиза, использование NlpCraft через maven central в данном случае будет недостаточно.
Общий принцип работы sugsyn достаточно прост. Он собирает примеры использования всех интентов запрашиваемой модели и объединяет их со всеми сконфигурированными синонимами каждого элемента модели. Созданные гибридные предложения посылаются на ContextWordServer, который возвращает рекомендации по использованию дополнительных слов в запрашиваемом контексте. Обратите внимание, для обучения нейронной сети требуются подготовленные и размеченные данные, но для работы sugsyn тоже требуются подготовленные данные — примеры использования, выигрыш в том, что данных для sugsyn нужно совсем немного, кроме того мы используем уже имеющиеся примеры из тестов системы.
Пример. Пусть некий элемент какой-то модели сконфигурирован с помощью двух синонимов: “ping“ и “buzz“ (сокращенный вариант модели, взятой из примера с будильником), и пусть единственный интент модели содержит два примера: «Ping me in 3 minutes» и «In an hour and 15mins, buzz me». Тогда sugsyn пошлет на ContextWordServer 4 запроса:
- text=”ping me in 3 minutes”, index=0
- text=”buzz me in 3 minutes”, index=0
- text=”in an hour and 15mins, ping me”, index=6
- text=”in an hour and 15mins, buzz me”, index=6
Это означает следующее — для каждого предложения (поле “text“) предложи мне какие-нибудь дополнительные подходящие слова, кроме уже имеющихся слов в позиции “index“. ContextWordServer вернет несколько вариантов, отсортированных по итоговому весу (комбинации результатов обеих моделей, влияние каждой модели может быть сконфигурировано), далее отсортированных по повторяемости.
Использование инструмента sugsyn
Приступим к работе
- Запускам ContextWordServer, то есть сервер с готовыми, предобученными моделями.
> cd ~/apache/incubator-nlpcraft/nlpcraft/src/main/python/ctxword
> ./bin/start_server.sh
Обратите внимание на то, что ContextWordServer должен быть предварительно проинсталирован и для успешной работы ему требуется python версий 3.6 — 3.8. См. “install_dependencies.sh“ для linux и mac или мануал по установке для windows. Имейте в виду, что процесс инсталляции влечет за собой скачивание файлов моделей существенных размеров, будьте внимательны. - Запускаем CLI, стартуем в нем server и probe с подготовленной моделью, подробности см. в разделе Quick Start. Для начальных экспериментов можно подготовить свою собственную модель или воспользоваться уже имеющимися в поставке примерами.
- Используем команду sugsyn, с одним обязательным параметром — идентификатором модели, которая должна быть уже запущена в probe. Второй, необязательный параметр — значение минимального коэффициента достоверности результата, поговорим о нем ниже.
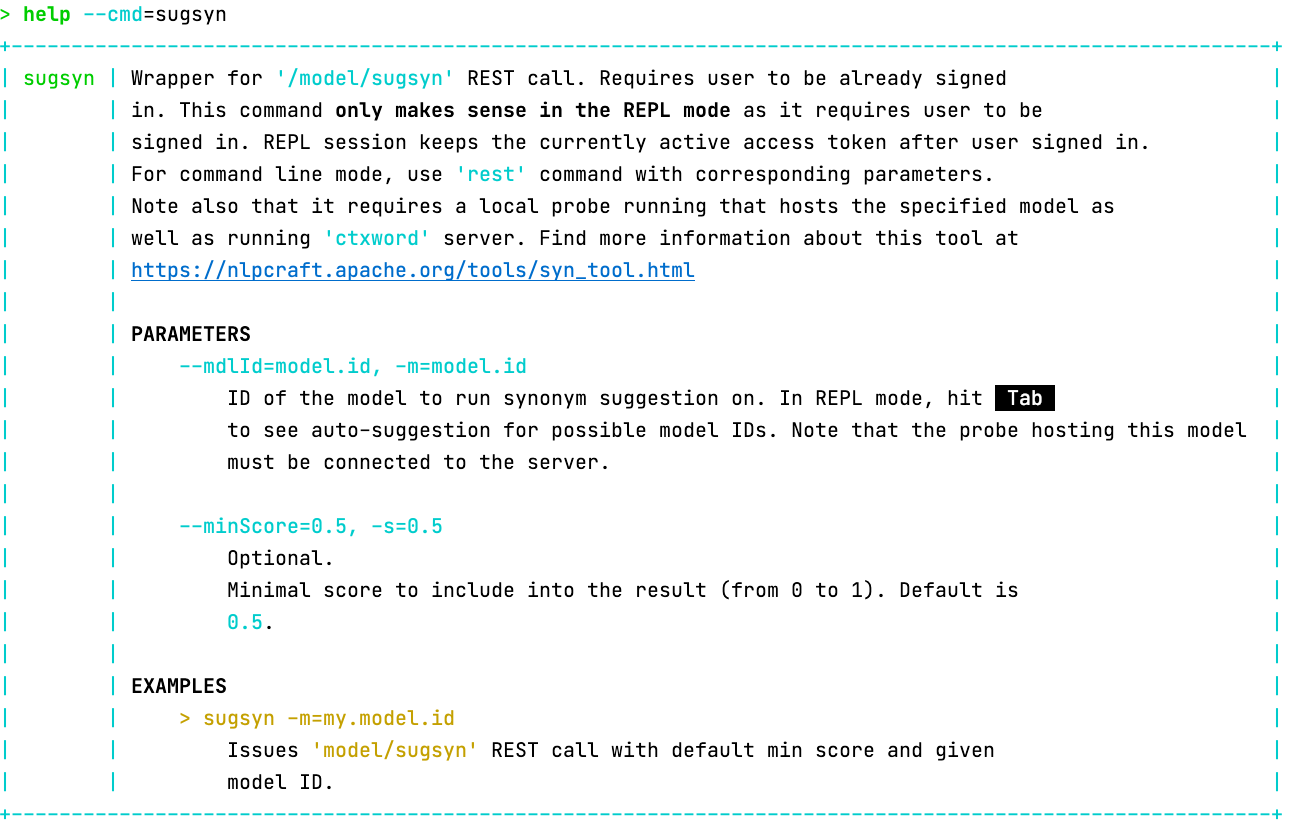
Все описанное выше расписано шаг за шагом в мануале по ссылке.
Получение результатов для разных моделей
Начнем с примера по прогнозу погоды. Элемент “wt:phen“ сконфигурирован с помощью множества синонимов среди которых «rain», «storm», «sun», «sunshine», «cloud», «dry» и т.д., а элемент “wt:fcast” с помощью «future», «forecast», «prognosis», «prediction» и т.д.
Вот часть ответа sugsyn на запрос со значением коэффициента minScore = 0.
> sugsyn —mdlId=nlpcraft.weather.ex —minScore=0
"wt:phen": [
{ "score": 1.00000, "synonym": "flooding" },
...
{ "score": 0.55013, "synonym": "freezing" },
...
{ "score": 0.09613, "synonym": "stop"},
{ "score": 0.09520, "synonym": "crash" },
{ "score": 0.09207, "synonym": "radar" },
...
"wt:fcast": [
{ "score": 1.00000, "synonym": "outlook" },
{ "score": 0.69549, "synonym": "news" },
{ "score": 0.68009, "synonym": "trend" },
...
{ "score": 0.04898, "synonym": "where" },
{ "score": 0.04848, "synonym": "classification" },
{ "score": 0.04826, "synonym": "the" },
...
Как мы видим из полученного ответа, чем больше значение коэффициента — тем выше ценность предложенных синонимов для элементов модели. Можно сказать, что интересные для использования синонимы здесь начинаются со значения коэффициента равного 0.5. Коэффициент достоверности результата — интегральный показатель, учитывающий коэффициенты выдачи моделей и частоту, с которой системой предлагается синоним в разных контекстах.
Посмотрим, что будет предложено в качестве дополнительных синонимов для элементов примера “умный дом”. Для “ls:loc”, описывающего расположение элементов освещения (синонимы: «kitchen», «library», «closet» и т.д.), предложенные варианты с высокими значениями коэффициента, большим чем 0.5, тоже выглядят заслуживающими внимания:
"lc:loc": [
{ "score": 1.00000, "synonym": "apartment" },
{ "score": 0.96921, "synonym": "bed" },
{ "score": 0.93816, "synonym": "area" },
{ "score": 0.91766, "synonym": "hall" },
...
{ "score": 0.53512, "synonym": "attic" },
{ "score": 0.51609, "synonym": "restroom" },
{ "score": 0.51055, "synonym": "street" },
{ "score": 0.48782, "synonym": "lounge" },
...
Но около коэффициента 0.5 для нашей модели уже попадается откровенный мусор — ”street”.
Для элемента “x:alarm” модели будильник, с синонимами: ”ping”, ”buzz”, ”wake”, ”call”, ”hit” и т.д. имеем следующий результат:
"x:alarm": [
{ "score": 1.00000, "synonym": "ask" },
{ "score": 0.94770, "synonym": "join" },
{ "score": 0.73308, "synonym": "remember" },
...
{ "score": 0.51398, "synonym": "stop" },
{ "score": 0.51369, "synonym": "kill" },
{ "score": 0.50011, "synonym": "send" },
...
То есть для элементов данной модели, с понижением коэффициента качество предложенных синонимов снижается заметно быстрее.
Для элемента “x:time” модели “текущее время“ (1, 2), с синонимами типа ”what time”, ”clock”, ”date time”, ”date and time” и т.д. имеем следующий результат:
"x:time": [
{ "score": 1.00000, "synonym": "night" },
{ "score": 0.92325, "synonym": "year" },
{ "score": 0.58671, "synonym": "place" },
{ "score": 0.55458, "synonym": "month" },
{ "score": 0.54937, "synonym": "events" },
{ "score": 0.54466, "synonym": "pictures"},
...
Качество предложенных синонимов оказалось неудовлетворительным даже при высоких коэффициентах.
Оценка результатов
Перечислим факторы, от которых зависит качество синонимов, предлагаемых sugsyn для поиска в тексте элементов модели:
- Количество синонимов, определенных пользователем в конфигурации элементов.
- Количество и качество примеров запросов к интентам. Под “качеством“ понимается естественность и распространенность добавленных примеров. Спросите гугл «который час», и число полученных результатов будет “примерно 2 630 000“. Спросите — «час который», результатов будет “примерно 136 000“. Текст первого запроса более качественный, и для примера он подойдет лучше.
- Самое главное и непредсказуемое — качество зависит от типа самого элемента и типа его модели.
Иными словами, даже при прочих равных условиях, таких как достаточное количество заранее сконфигурированных синонимов и примеров использования, для некоторых видов сущностей нейронная сеть предложит более качественный набор синонимов, а для некоторых менее качественный, и это зависит от природы самих сущностей и моделей. То есть для достижения сопоставимого уровня качества поиска, выбирая из списка предлагаемых к использованию синонимов, для разных элементов и разных моделей мы должны использовать разные значения минимального коэффициента достоверности предлагаемых вариантов. В целом это вполне объяснимо, так как даже одни и те же слова в разных смысловых контекстах могут быть заменены несколько разными наборами слов заменителей. Предобученная модель, используемая по умолчанию с ContectWordServer может быть адаптирована для одних типов сущностей лучше чем для других, однако перенастройка модели может и не улучшить итоговый результат. Так как Apache NlpCraft — это opensource решение, вы всегда можете изменить все настройки модели, как параметры, так и саму модель с учетом специфики вашей предметной области. К примеру, для специфичной, изолированной области, имеет смысл обучить модель bert с нуля, поскольку данных об этой области в “стандартной” модели может оказаться недостаточно.
При работе с sugsyn, помимо идентификатора модели, вы можете использовать всего один параметр — minScore, просто ограничивая размер выборки синонимов, отсортированных в порядке снижения их качества. Подобное упрощение используется для облегчения работы специалистов, ответственных за расширение списка синонимов элементов настраиваемой модели. Обилие конфигурационных параметров, свойственное работе с нейронными сетями в данном случае способно лишь запутать пользователей системы.
Заключение
Если вы полностью делегируете задачу поиска ваших сущностей нейронным сетям, то для разных элементов и разных типов моделей вы будете получать результаты, заметно отличающиеся качеством распознавания. При этом вы даже не сможете оценить эту разницу, особенно если вы не контролируете настройки сети. Но и самостоятельная конфигурация для установки желаемого порога срабатывания, не будет являться простой задачей. Причиной, как правило, является недостаток достаточного количества данных, необходимых для корректного обучения и тестирования сети. Используя предлагаемый Apache NlpCraft механизм поиска сущностей через набор синонимов и инструмент, предлагающий варианты обогащения данного списка, вы можете самостоятельно контролировать степень достоверности синонимов вашей модели и выбрать из предлагаемых сетью только одобренные вами подходящие варианты. Фактически вы получаете возможность заглянуть в черный ящик и достать из него лишь то, что вам нужно.
По вашему запросу найдено: реализация нечеткого поиска
Время на прочтение
8 мин
Количество просмотров 9.9K
Все мы совершаем ошибки: в данном случае речь идет о поисковых запросах. Количество сайтов для продажи товаров и услуг растет наряду с потребностями пользователей, однако не всегда они могут найти то, что ищут – только потому, что неправильно вводят название необходимого товара. Решение данной проблемы достигается путем реализации нечеткого поиска, то есть использования алгоритма поиска наиболее близких значений с учетом возможных ошибок или опечаток пользователя. Область применения такого поиска достаточно широка – нам же удалось поработать над поиском для крупного интернет-магазина в фудритейл-сегменте.
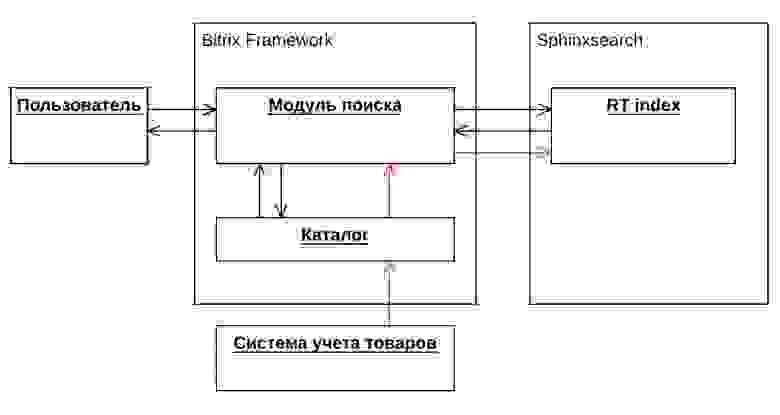
Исходное состояние поиска
Интернет-магазин разрабатывался на платформе «1С-Битрикс: Управление сайтом». Для реализации поиска мы использовали стандартный модуль поиска системы bitrix и полнотекстовый движок sphinxsearch. В sphinxsearch был применен тип индекса Real Time (RT), который не требует статичного источника данных, а может быть наполнен в любой момент в реальном времени. Это позволяет гибко обновлять поисковой индекс без его полной переиндексации. Поскольку RT индекс в качестве протокола запросов использует только SphinxQL, интеграция осуществлялась именно через него. SphinxQL — mysql-подобный протокол запросов, который реализует возможность подключения через стандартных mysql-клиентов, при этом предоставляет sql-синтаксис с некоторыми ограничениями и своими особенностями. В модуле поиска используются запросы select/insert/replace/delete.
В системе bitrix производился процесс индексации данных товаров, категорий и брендов. Информация по данным сущностям передавалась в sphinx, который в свою очередь производил обновление RT индекса. При обновлении данных в интернет-магазине срабатывает событие, которое обновляет данные в Sphinx. Консистентность данных осуществляется через идентификатор сущности в интернет-магазине.
Когда пользователь производит поиск в интернет-магазине, система производит запрос с поисковой фразой в Sphinx и получает идентификаторы сущностей, также производит выборку из базы информации по ним и формирует страницу с результатами поисковой выдачи.
На момент начала решения проблемы нечеткого поиска общая схема архитектуры поиска на проекте выглядела следующим образом:
Выбор технологий
Перед нами стояла задача: угадать запрос пользователя, который, возможно, содержит опечатки. Для этого нам необходимо проанализировать каждое слово в запросе и решить, правильно ли его написал пользователь или нет. В случае ошибки следовало подобрать наиболее подходящие варианты. Определение правильности написания слов невозможно без базы слов и словоформ того языка, на котором мы хотим их угадывать. Упрощенно такую базу можно назвать словарем — именно он нам был необходим.
Для подбора вариантов замен для слов, введенных с ошибкой, была выбрана популярная формула расчета расстояния Дамерау–Левенштейна. Данная формула представляет собой алгоритм сравнения двух слов. Результатом сравнения является количество операций для преобразования одного слова в другое. Первоначально расстояние Левенштейна предполагает использование 3-х операций:
- вставка
- удаление
- замена
Расстояние Дамерау-Левенштейна является при этом расширенной версией расстояния Левенштейна и добавляет еще одну операцию: транспозицию, то есть перестановку двух соседних символов.
Таким образом, количество полученных операций становится количеством ошибок, допущенных пользователем при написании слова. Мы выбрали ограничение в две ошибки, поскольку большее количество не имело смысла: в этом случае мы получаем слишком много вариантов для замены, что повышает вероятность промаха.
Для более релевантного поиска вариантов слов, похожих по звучанию, использована функция metaphone — данная функция преобразует слово в его фонетическую форму. К сожалению, metaphone работает только с буквами английского алфавита, поэтому перед вычислением фонетической формы мы производим транслитерацию слова. Значение фонетической формы хранится в словаре, а также вычисляется в запросе пользователя. Полученные в итоге значения сравниваются функцией расстояния Дамерау-Левенштейна.
Словарь хранится в базе данных MySQL. Чтобы не загружать словарь в память приложения, было решено производить расчет расстояния Дамерау-Левенштейна на стороне базы. Пользовательская функция для вычисления расстояния Дамерау-Левенштейна, написанная на основе функции на Си, написанной Линусом Торвальдсом, вполне удовлетворяла нашим требованиям. Автор функции Diego Torres.
После расчета расстояния Дамерау-Левенштейна нужно было отсортировать результаты по степени сходства для выбора наиболее подходящего. Для этого мы использовали алгоритм Оливера: вычисление схожести двух строк. В php данный алгоритм представлен функцией similar_text. Первые два параметра функции принимают на вход строки, которые необходимо сравнить.Порядок сравнения строк важен, так как функция выдает разные значения в зависимости от того, в каком порядке строки переданы в функцию. Третьим параметром должна быть передана переменная, в которую помещается результат сравнения. Это будет число от 0 до 100, что означает процентное соотношение похожести двух строк. После вычисления результаты сортируются по убыванию процента схожести, далее выбираются варианты с лучшими значениями.
Так как вычисление расстояние Дамерау-Левенштейна производилось по транскрипции слова, в результаты попадали слова с не совсем релевантными значениями. В связи с этим мы ограничили выборку вариантов с процентом совпадения больше 70%.
В процессе разработки мы заметили, что наш алгоритм может угадывать слова на разных раскладках. Поэтому нам было необходимо расширить словарь, добавив в него значения слов на обратной раскладке. В требованиях к поиску фигурировали только две раскладки: русская и английская. Каждое слово поискового запроса пользователя мы дублировали на обратной раскладке и добавляли обработку расчета расстояния Дамерау-Левенштейна. Варианты для прямой и обратной раскладки обрабатываются независимо друг от друга, выбираются варианты с наибольшим процентом схожести. Только для вариантов с обратной раскладкой значением для исправленного поискового запроса будет слово в прямой раскладке.
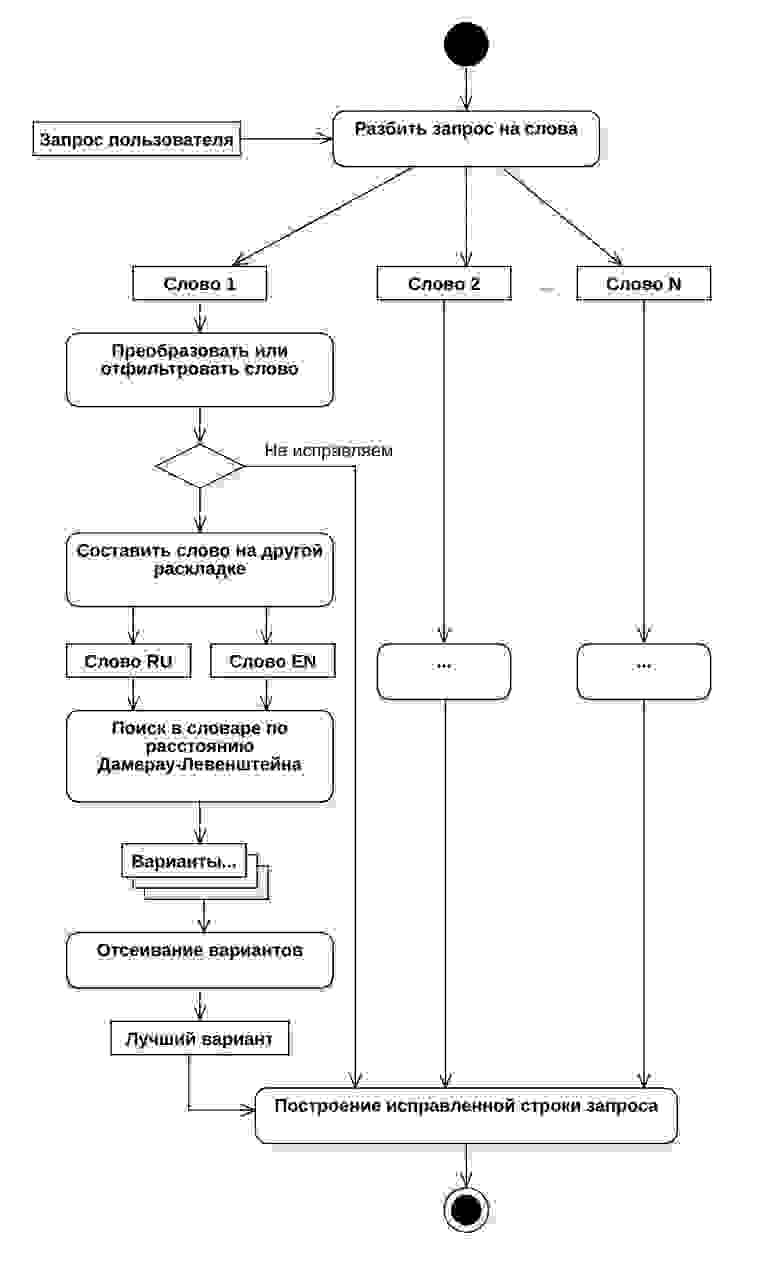
Алгоритм нечеткого поиска
Таким образом сформировался алгоритм действий из 6 основных шагов. В процессе тестирования мы выяснили, что не все слова в запросах пользователей нужно обрабатывать в исходном виде или обрабатывать вообще. Для решения подобных случаев был введен дополнительный шаг, который мы назвали преобразователем или же фильтром. В результате, конечный алгоритм состоял из 7 шагов:
- Разбить запрос на отдельные слова;
- Пропустить каждое слово через преобразователь (о нем далее);
- Для каждого слова составить его форму на другой раскладке;
- Составить транскрипцию;
- Произвести запрос поиска в таблице словаря, сравнивая каждую запись через расстояние Дамерау-Левенштейна;
- Оставить только записи с расстоянием, меньшим или равным двум;
- Через алгоритм Оливера оставить только слова с процентом схожести больше 70%
Схематически данный алгоритм выглядит следующим образом:
Функционал преобразования и фильтрации слов
Когда мы начали тестировать первый прототип без преобразователя, стало очевидно, что нет необходимости пытаться угадывать все слова в запросе пользователя. Для данных ограничений был создан преобразователь. Он позволяет преобразовывать слова в нужный нам вид и отсеивать те, которые, как мы считаем, пытаться угадывать не нужно.
Изначально было решено, что минимальная длина слова, которое следует пропускать через алгоритм, должна быть не менее двух символов. Ведь если пользователь ввел предлог или союз из одного символа, то вероятность угадать практически минимальна. Вторым шагом стало разбиение запроса на слова. В первую очередь мы выбрали набор символов, которые могут содержать слова: буквы, цифры, точка и дефис (тире). Пробелы и остальные символы являются разделителями слов.
Очень часто пользователи вводят числа для указания объема или количества. В этом случае будет некорректно исправлять подобный запрос. Например, пользователь ввел запрос “вода 1,1 литров”. Если мы исправим его запрос на 1,5 или 1,0 — это будет неправильно. В таких случаях мы решили пропускать слова с цифрой. Они, минуя наш алгоритм, передаются в полнотекстовый поиск Sphinx.
Еще одно преобразование связано с точками в названиях брендов — например: Dr.Pepper или Mr.Proper. В случаях, если в середине слова находится символ точки, то мы разбиваем его на два, добавляя пробел. Второй кейс с точкой в середине слова — здесь мы вспоминаем бренды-аббревиатуры. Например, бренд R.O.C.S. — в этом случае мы вырезаем точки и получаем единое слово. Данное преобразование работает, если между точками стоит только одна буква.
В случаях присутствия в слове дефис (тире), следует разбить слово на несколько и попробовать угадать их по отдельности, а затем склеить вместе наилучшие варианты.
В итоге для наиболее точного распознавания запроса был разработан преобразователь — большую часть работы по настройке всего функционала заняла именно эта разработка. Во многом благодаря ему производится корректировка и настройка всего нечеткого поиска. Кратко повторим правила, по которым производится отсеивание и преобразование слов:
- слово должно быть длиннее 2-х символов
- в слове должны содержаться только буквы, символ точки и символ дефис (тире)
- если точка находится в середине слова, после нее добавляется пробел
- если это аббревиатура — точки вырезаются, а буквы склеиваются
- не пытаться угадать слово, если в нем присутствует цифра
- если в слове содержится дефис (тире), то разбить его на несколько, производить поиск по отдельности и в конце склеить
Составление словаря
Как было упомянуто ранее, чтобы исправить запрос пользователя, необходимо определять, какие слова написаны с ошибкой, а какие нет. Для этого в системе был создан словарь, где должны содержаться слова с правильным написанием.
На первом этапе встал вопрос о наполнении словаря — в результате для его составления мы решили использовать контент каталога. Так как информация по товарам время от времени импортировалась из внешней системы и индексировалась для системы полнотекстового поиска Sphinx, было решено добавить функционал составления словаря на этом этапе. Мы следовали следующей логике: если слова нет в контенте товаров, то к чему пытаться его угадать?
Информация о товаре объединялась в общий текст и проводилась через преобразователь. Режим работы преобразователя был немного модифицирован: при разбиении слов через дефис (тире) в словарь сохранялась каждая из частей отдельно, при замене точек в словарь добавляются исходные и измененные данные. И поскольку при сравнении слов для вычисления расстояния Дамерау-Левенштейна используется транскрипция слова, дополнительно в словарь добавляется транскрипция.
В контенте товаров было много опечаток, для этого в словаре заложен флаг, при установке которого слово больше не используется в поиске. Контент из 35 тыс. товаров позволил создать словарь из 100 тыс. уникальных слов, которого в итоге оказалось недостаточно для некоторых запросов пользователя. В связи с этим пришлось предусмотреть функционал загрузки для его обогащения. Была создана консольная команда, позволяющая загружать словари. Формат файлов с данными словарей должен соответствовать csv. Каждая запись содержит только одно поле с самим полем словаря. Для того, чтобы загруженные данные можно было отличить от данных, сгенерированных на основе контента товаров, был добавлен специальный флаг.
В итоге таблица словаря имеет следующую схему:
| Название поля | Тип поля |
|---|---|
| Слово | string |
| Транскрипция | string |
| Добавлено вручную | bool |
| Не использовать | bool |
До разработки функционала нечеткого поиска в товарах присутствовали поля, которые содержали набор слов с опечатками. При первом прогоне генерации словаря они попали в его контент. В итоге был получен словарь с опечатками, контент которого не подходил для корректной работы функционала. Поэтому была добавлена еще одна консольная команда, которая имела обратную функциональность генерации словаря. Используя контент заданного поля товаров, команда производила поиск слов в словаре и очищала их из словаря. После очистки подобные поля исключались из индексации.
Интеграция в Bitrix
Для реализации минимального необходимого функционала было создано три класса:
- DictionaryTable — ORM системы Битрикс для работы со словарем
- Dictionary — класс формирования словаря
- Search — класс реализации поиска
Для интеграции в Битрикс потребовалось внести изменения в 2 компонента:
- bitrix:search.page
- bitrix.search.title
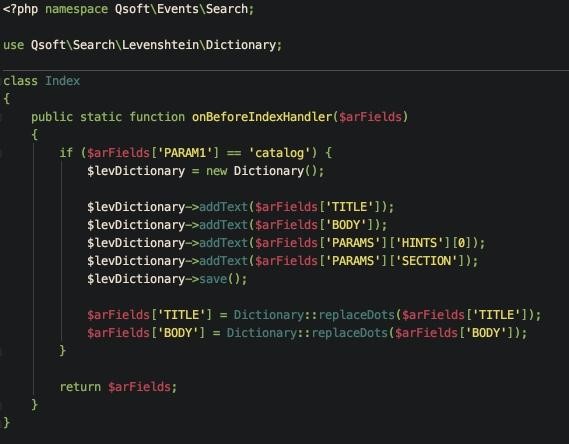
Перед выполнением запроса вызывается метод обработки для выявления ошибок и подбора подходящих вариантов:
![]()
Для составления словаря было зарегистрировано событие на индексацию поисковым модулем элементов инфоблока с товарами (search:BeforeIndex).
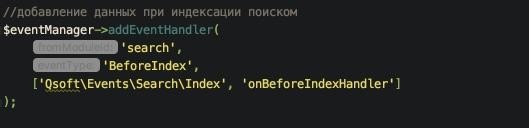
Планы на будущее
Данный подход не идеален с точки зрения производительности. При увеличении размера словаря до 1М+ слов время ответа базы может увеличится в разы. Пока словарь небольшой, производительность нас устраивает. Возможно, в дальнейшем придется реализовать алгоритм через автомат Левенштейна или префиксное дерево.
Заключение
Итак, ни одна поисковая система не избавлена от появления запросов, нарушающих общепринятые правила орфографии — будь то случайная опечатка или реальное незнание написания слов. Поэтому даже не прибегая к классическим вариантам нечеткого поиска Google или Яндекс можно создать свой собственный, благодаря которому и пользователь, и владелец сайта смогут получить желаемый результат.
Код нашей реализации можно посмотреть в репозитории: github.com/qsoft-dev/damlev-bitrix
Месяц в подарок — 30 дней демо-период
ПРИМЕРЫ ПОИСКОВЫХ ЗАПРОСОВ
газАвая гАрелка — находит газовые горелки, товары в наличии выводятся вперёд
бокер — находит товары производителя Böker
тАчилка лански — находит тОчилки производителя Lansky
зОтАчить нАжЫк — находит товары для заточки ножей, товары в наличии выводятся вперёд
воТкО — находит товары, содержащие водку
свИтильник для чтеня — находит товары для чтения, относящиеся к светильникам, несмотря на опечатки и пропущенные буквы в запросе
арех — найдет товары с орехом в названии, так, например, и с видами орехов — фундук, миндаль и подобное
сОрЛелька — не найдет сАрДельки, потому что их нет на сайте, зато предложит сосиски
ПРЕВЕТ, ВЫ ПА АДРИСУ!
Все мы знаем, как часто люди пытаются что-то найти на сайте, допуская ошибки в словах или опечатываясь в спешке, либо вводя названия кириллицей.
Этот модуль достаточно успешно разрешает эти ситуации, помогая посетителям находить нужный товар и услугу, увеличивая конверсию.
Множество сайтов его уже успешно используют:
- https://fsin-pokupka.ru
- https://nojinsk.ru
- https://dom-decora.ru
- https://ribomaniya.ru
- https://jimbobar.ru
- https://dancehelp.ru
и если хотите, впишем ваш сайт в этот список.
Данный модуль ищет по названию товара и разделам, seo-тегам, а также по свойствам, разрешенным к индексации модулем поиска или выводимых в умном фильтре.
Модуль облегчает поиск:
- Выстраивает релевантность выдачи по наличию товаров в продаже;
- Производит поиск по свойствам элементов и товаров, а так же seo-тегам;
- При вводе искомой фразы с разнообразными опечатками;
- По сходству символов на английском и кириллице, например, А1234В можно ввести и кириллицей и латиницей;
- Через ассоциативные ряды, например, при поиске воды может порекомендовать ведро, если по прямому запросу ничего не нашлось;
- Комбинация различных алгоритмов нечеткого поиска и машинного обучения;
СТАТИСТИКА ПОИСКА
Модулем ведётся стандартная статистика, какие поисковые запросы использовались и сколько по ним нашлось результатов — полезно для анализа спроса своей аудитории.
SEO ДЛЯ СТРАНИЦ РЕЗУЛЬТАТОВ ПОИСКА (В МАЕ)
Можно указывать как шаблоны для генерации SEO мета-тегов страниц результатов поиска относительно искомой фразы, так и конкретные SEO-данные для конкретной поисковой фразы.
ДАННЫЕ В БЕЗОПАСНОСТИ
Данные обезличенно хранятся в специализированном поисковом индексе с привязкой к хэшу вашей лицензии 1С-Битрикс и ip-адреса вашего сервера. Это защитит от попыток взлома ваших данных, либо восстановления информации о владельце данных, при несанкционированном доступе к ним. Также данные автоматически удаляются из сервиса при отсутствии попыток поиска по индексу в течение 30 дней.
Интеграция улучшенного умного поиск товаров и услуг в 1С-Битрикс
Для начала, установите модуль:
Установить модуль
После установки модуля необходимо согласиться с отправкой и обработкой данных
Далее надо произвести первичную настройку модуля.
1. Выбрать вкладку с нужным сайтом
2. Настроить индексацию
Нажмите «Применить» внизу страницы, что бы обновился список свойств возле каждого инфоблока.
3. Убедиться, что для инфоблоков указаны все свойства, которые необходимо индексировать, а так же нет лишних.
Если видите лишние свойства или каких-то свойств не хватает, нажмите «настройки» возле названия инфоблока и перенастройте индексацию свойств.
Для свойств которые должны попадать в поисковый индекс должна стоять галочка «Значения свойства участвуют в поиске», либо «Показывать в умном фильтре» и выбраны соответствующие галочки в пункте 2.
4. Нажать «Применить»

Далее необходимо произвести переиндексацию.
Для этого переходим по ссылке «переиндексация поиска» вверху или внизу страницы настроек модуля.
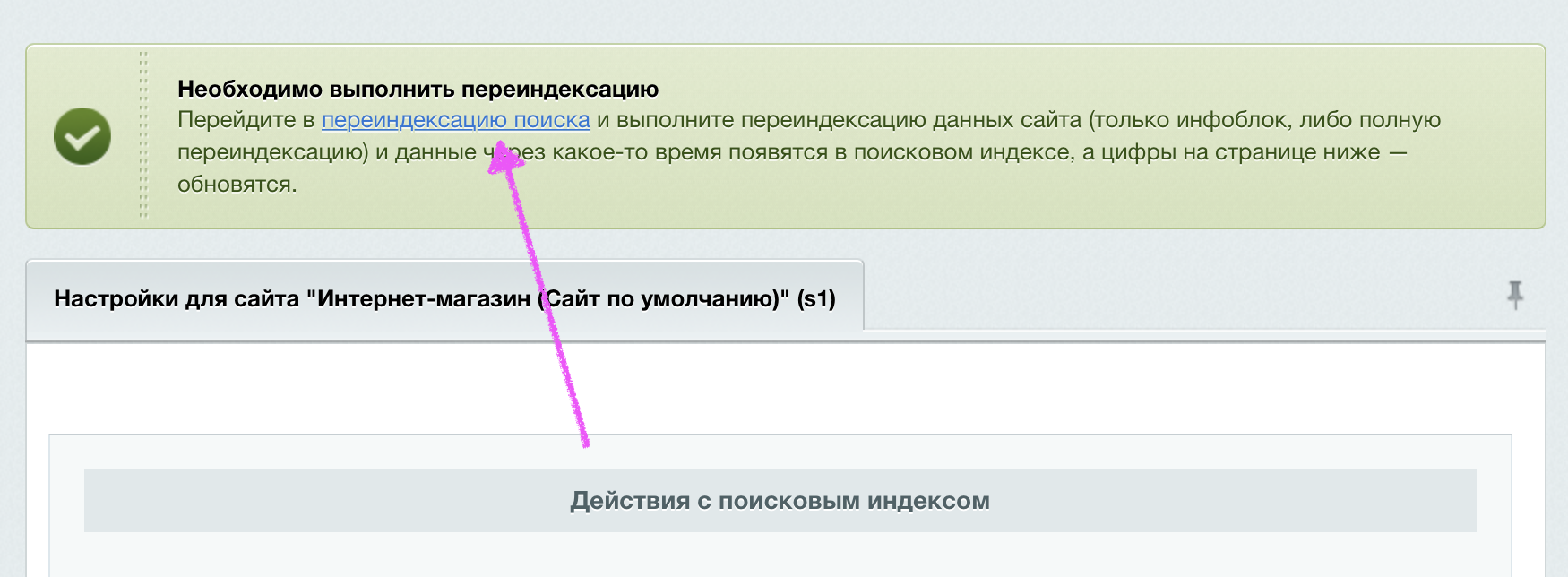
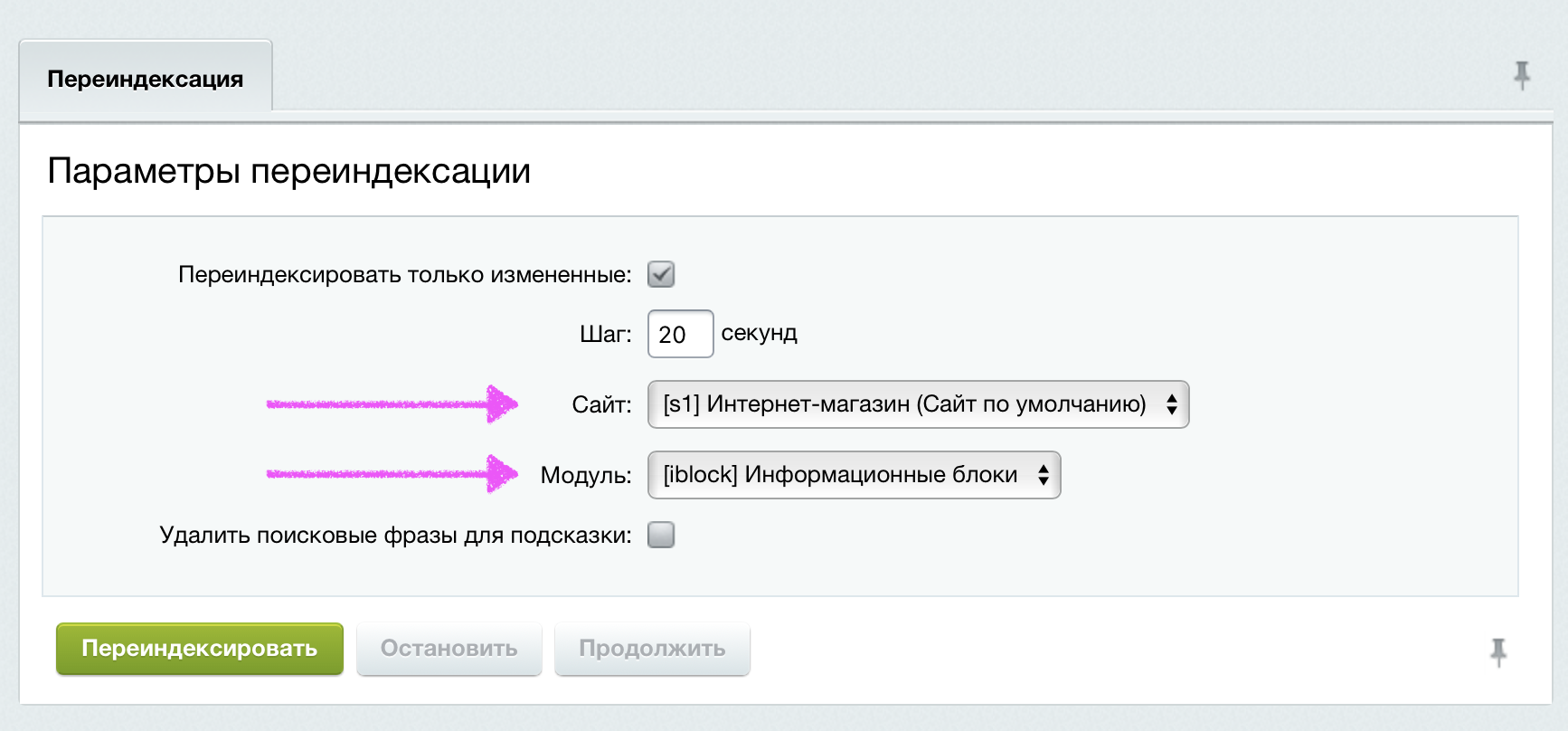
Необходимо выбрать нужный сайт и модуль «Информационные блоки», если индексировать необходимо только один сайт.
Так же можно убрать галочку «Переиндексировать только измененные» и произвести полную переиндексацию всех сайтов и модулей.
Всё. Теперь данные отправились в индекс и спустя минуту будут доступны для поиска.
Пока данные обрабатываются в индексе, необходимо заменить вызов компонент bitrix на новые.
Иначе настраивайте по следующему алгоритму:
1. заменить везде вызов bitrix:search.title на itd:search.title , скопировав кастомизированные шаблоны от bitrix:search.title в пространство itd:search.title шаблона вашего сайта


2. заменить по аналогии везде вызов bitrix:search.page на на itd:search.page
3. если у вас используется компонент search.page в каталоге (catalog.search), то необходимо доработать шаблон catalog.search, добавив перед подключением компонента bitrix:search.page
$arElements = $APPLICATION->IncludeComponent("bitrix:search.page"...
конструкцию вида
if (BitrixMainLoader::includeModule('itd.search')) {
$arElements = ITDSearchIndex::findIdsNotExactOnlyElements($_REQUEST['q'], [$arParams['IBLOCK_ID']], SITE_ID, 100);
}
А так же обернуть подключение компонента search.page в проверку
if (empty($arElements)) { $arElements = $APPLICATION->IncludeComponent("bitrix:search.page"...
Что будет обозначать, что если сервис поиска не вернет результатов по какой-то причине, то подключится стандартный поиск битрикса.
Для вывода элементов в порядке релевантности (наиболее подходящие в начале), в компонент search.page или catalog.section, смотря в какой передаете $arElements, необходимо указать сортировку
"ELEMENT_SORT_FIELD" => 'id', "ELEMENT_SORT_ORDER" => $arElements,
подробнее про этот функционал сортировки описан в документации битрикс
Теперь осталось вернуться на страницу настроек модуля и обновить её.
Внизу страницы вы должны увидеть информацию о последних добавленных в индекс элементах
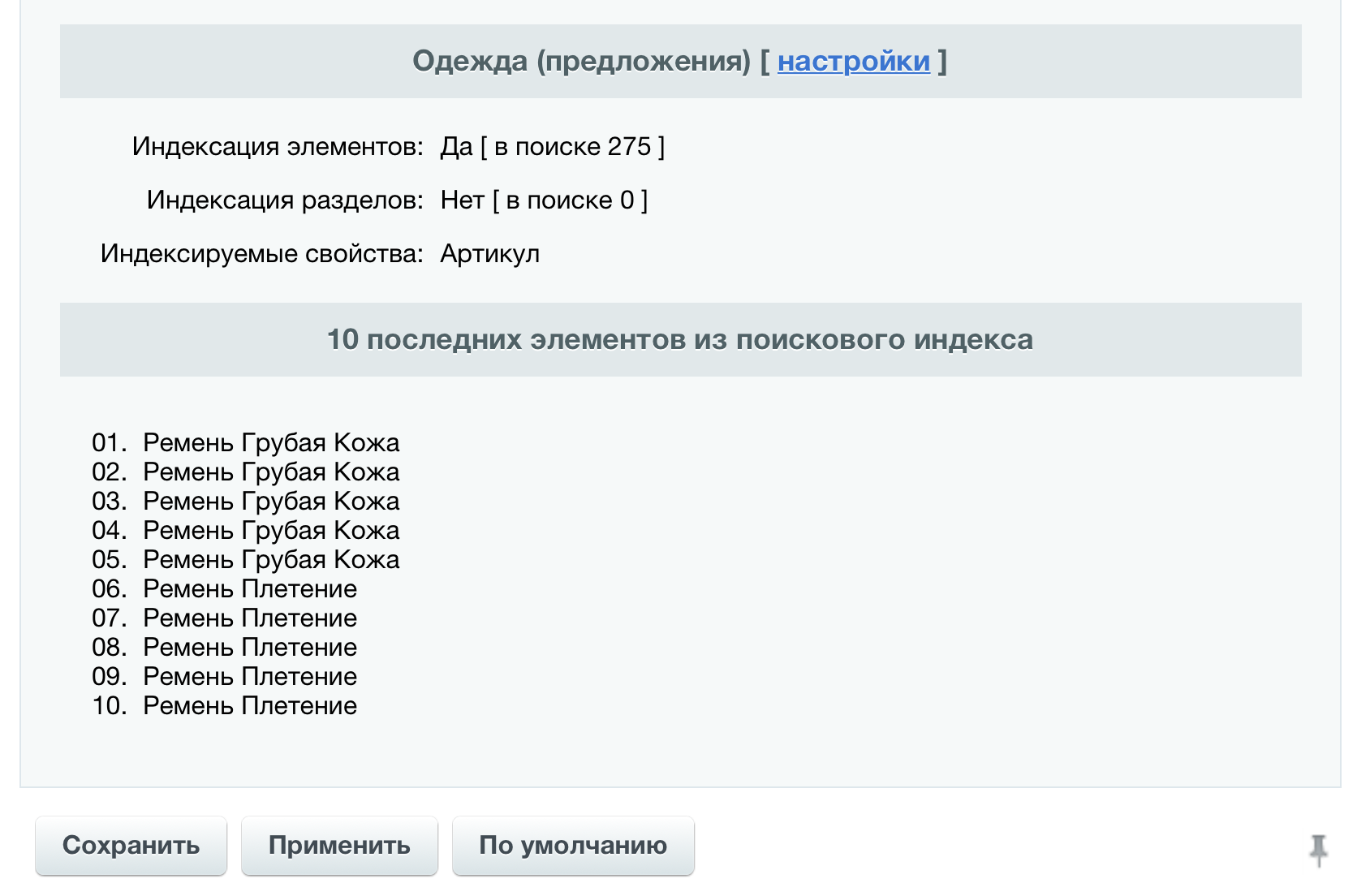
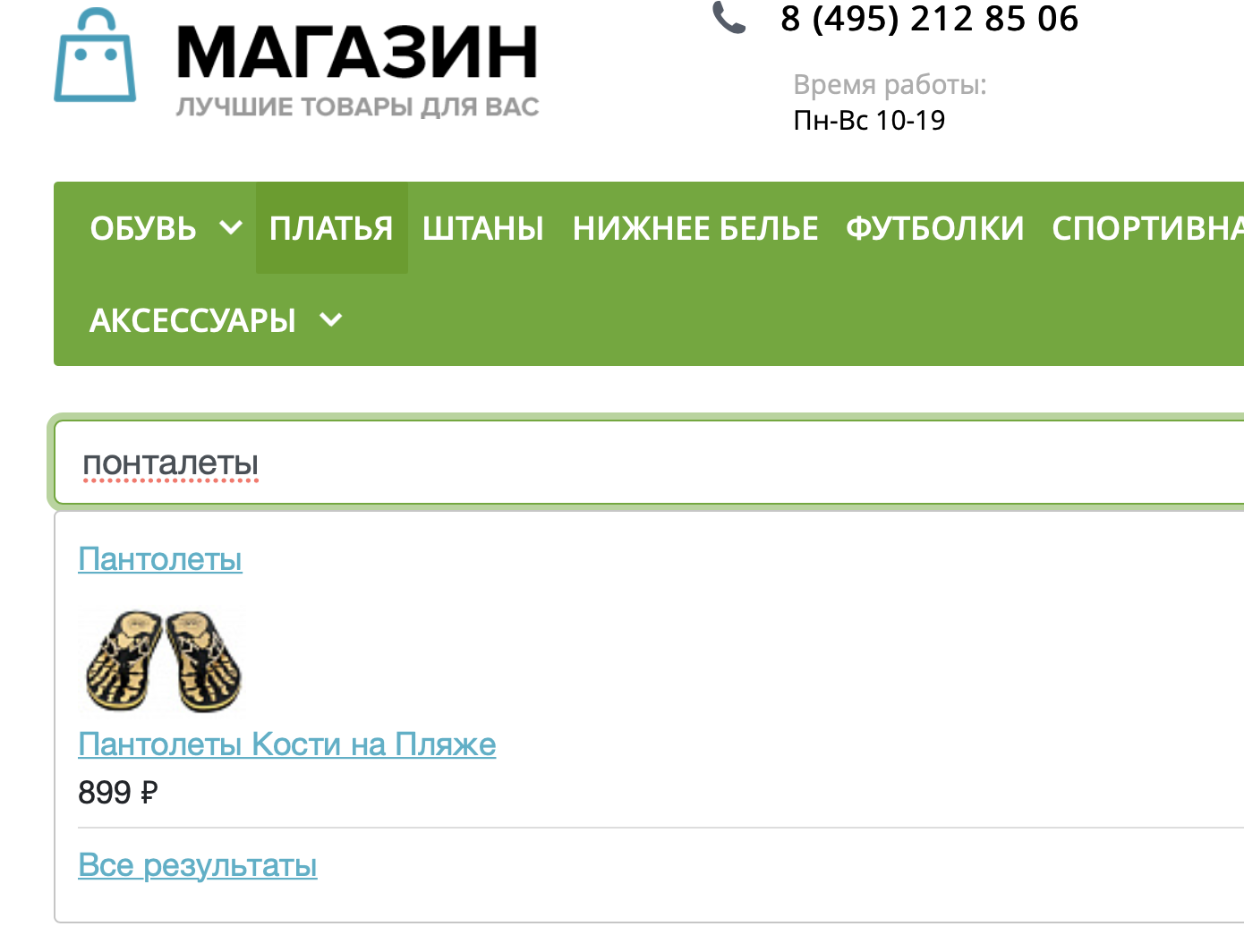
Если элементы начали появляться в блоке «10 последний элементов из поискового индекса», то теперь можно пойти на сайт и попробовать поискать.
Поздравляем!
Если у вас остались вопросы, то напишите нам в техподдержку.